
TLDR:
I used Understand’s CodeCheck feature to examine an influential COVID infection simulation program from Imperial College in the UK as it existed in March 2020 when it was being used to advise world leaders.
I did not run or execute the software, instead, looking at it purely from a static source code only perspective.
CodeCheck reported 1287 issues – many of which were problematic but not show stoppers. However, serious problems it found include possible floating-point precision errors, large areas of unmaintainable code, and odd uses of constants in unexplained ways that make the code hard to trust and difficult to modify/enhance.
My professional sense is that this code is unmaintainable and is littered with unknown and unfindable bugs.
Code with a purpose this important and whose use is so impactful should be refactored and re-written using modern coding conventions by professional developers safely, maintainably, and correctly implementing the science as explained and tested by epidemiologist researchers.
I also recommend they use static analysis tools as a matter of course. I know we will gladly supply whatever we have that would help, and I’m sure so would other vendors in the static analysis and code quality space.
Details
Last year, while locked down, I read a few articles where experienced programmers reviewed the source code of a COVID epidemiology model from Imperial College in England. It had been used by policymakers around the world.
The reviews were fairly negative, which I wasn’t sure was due to technical or political reasons. This being the issue of the day (or decade), I decided to look at the code myself.
About the Code
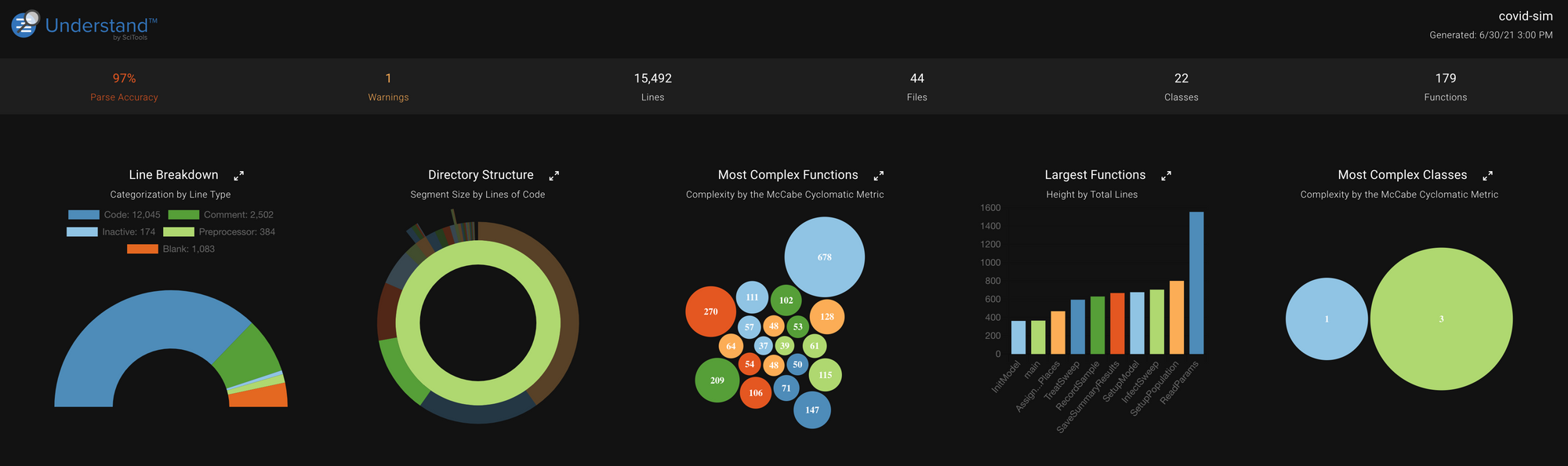
“Covid-Sim” has 15K lines of C++ code, in one directory and 47 header and source files. Here are the file dependencies, which initially gave me pause as it is very very “connected”, some cyclically.
Also, on inspection, it looked like some of the code (rand.cpp) dated back to the ’80s and was automatically converted FORTRAN code.

Getting the Source Code
The code comes from this GitHub repository:
https://github.com/mrc-ide/covid-sim
which you can bring down to your computer using this command:
git clone https://github.com/mrc-ide/covid-sim.git
The code has been updated extensively in the last year. I’m going to look at it as it was in March of 2020. To check out the code at the version I’m using use this command:
git checkout 2839d9958f560633863c6fa49df218cee6ea63df
First Analysis – Compiler warnings with an eye towards portability
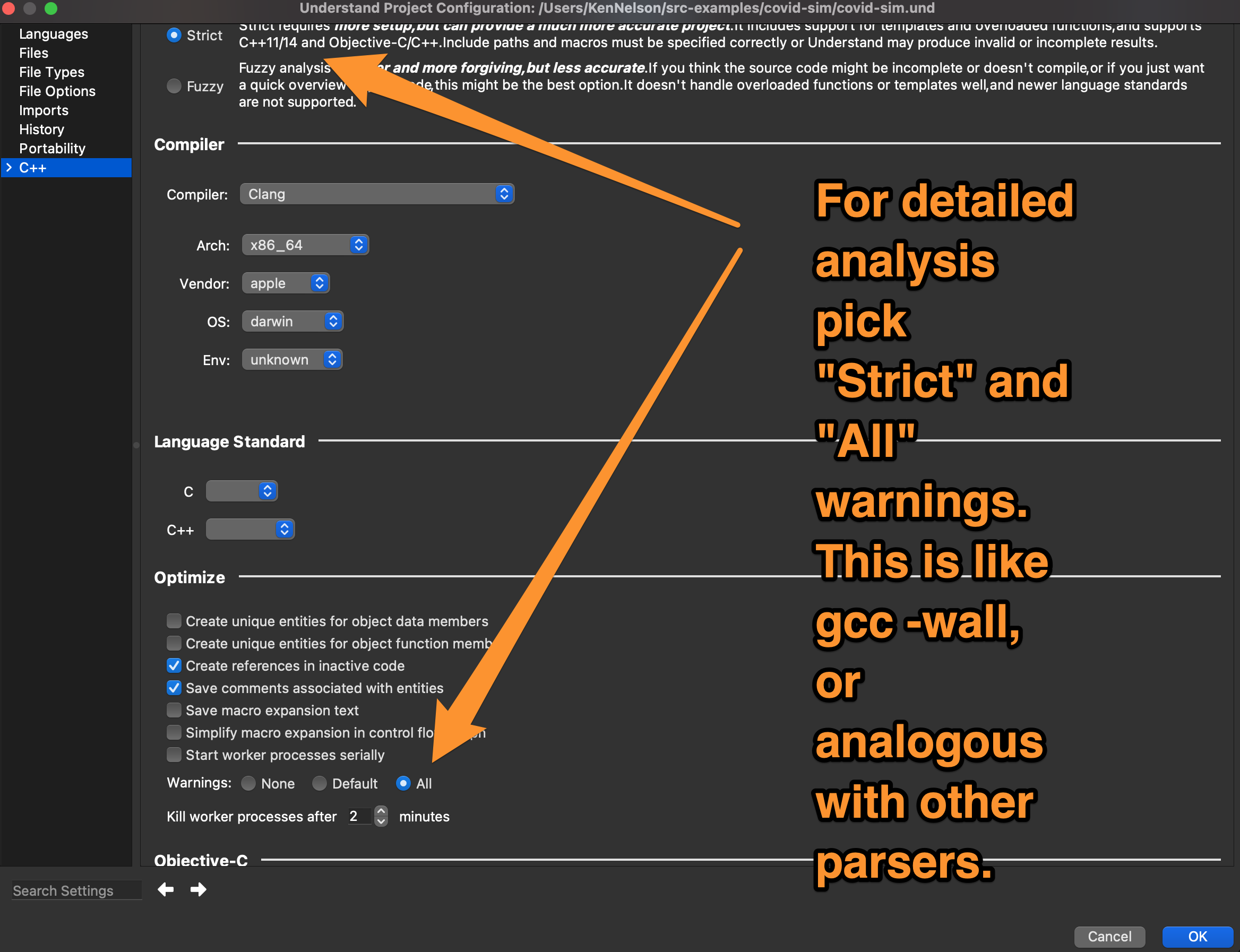
The first thing I did was use the project’s Microsoft Visual Studio solution (.sln) file to specify the Understand project configurations, this basically just required me to aim Understand at the source code I’d checked out. It found what it needed automagically from there.
Prior to that, I’d set the parse warnings to “All”, so I could get a sense of what the parser was finding that may be incorrect or not-portable code.
I then parsed the code, which only took a few seconds for 15,000 lines of code. Understand parsed it successfully and gave me one warning:
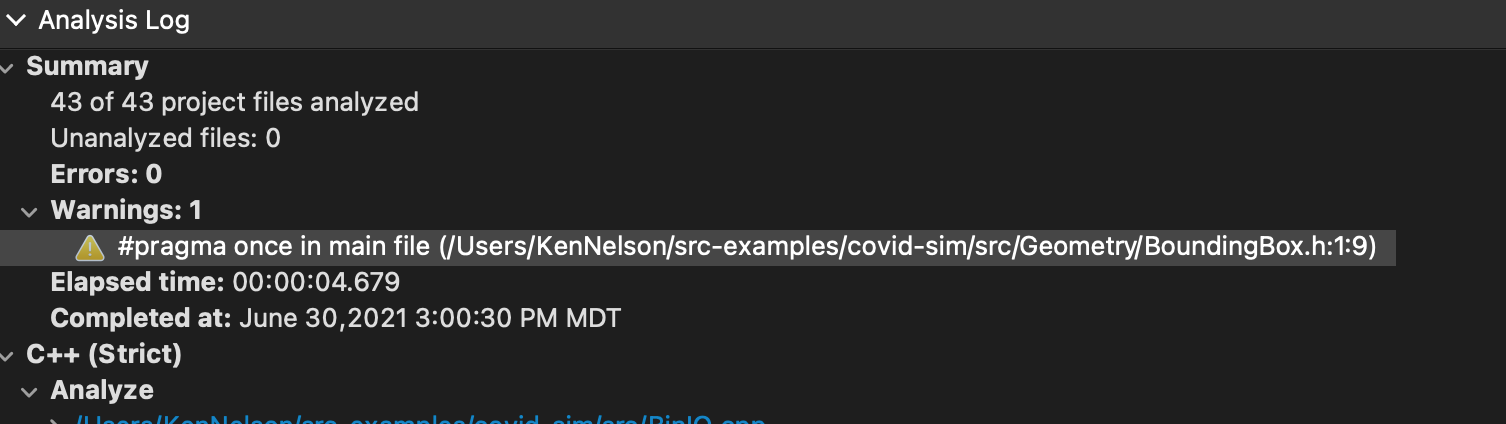
“#pragma once” is a widely supported, but non-standard, pragma meant to help avoid include guards (#ifndef SOMEMACRO #else #endif).
It cleans up your code, is concise and readable, and I don’t consider it necessarily a bad coding practice that will lead to unknown runtime errors as a compiler that doesn’t support it will warn you about an unknown pragma.
Now I had a clean parse – no syntax errors, and no warnings from the parser. That is a terrific start!
I was ready to start using CodeCheck.
What to check?
Understand offers hundreds of code-checks. I decided to focus on three classes of problems:
- Portability issues that might explain reports of different answers on different compilers/systems.
- Precision errors relating to floating-point calculations and large-scale math, which are the core purpose of this code.
- Coding practices where maintenance is likely to have caused bugs, or that would make it hard to adapt the model as we learned more thru the pandemic.
Checks, Results, and Commentary
Commented Out Code
Personal peeve… I hate commented-out code. I always check this. It’s a sign of maintenance where the programmer isn’t really sure what is going on and they are commenting out from hope, not knowledge. It’s also a sign that maybe they want to bring this code back, but will the context be the same… nope. Bad idea.
CodeCheck found 43 instances of commented-out code. I focused on 19 instances in the core covid simulation file “covidsim.cpp”.
Some were obviously commented out debug statements:

These are not “bad” per se. They indicate a lack of training and experience on the part of the developers because there are ways to find out what is happening in your code without littering it with comments, as well as ways to do this via log files controlled by runtime switches, or even in the debugger. Using this comment/uncomment method it is very easy to have unintended code running with your desired code. Debugging like this acts as a “proxy” for a bad coder, but maybe a good scientist.
This one (and others like it) concern me:
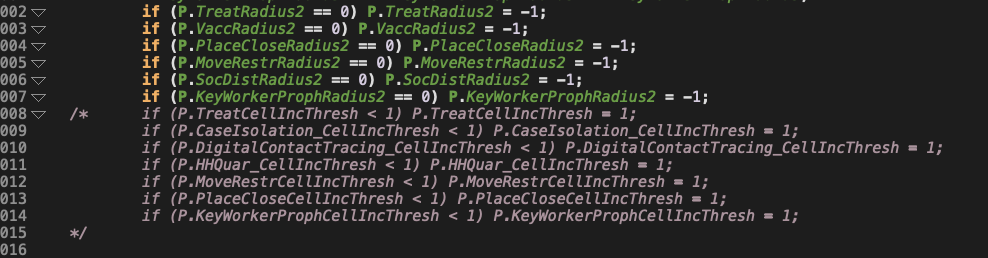
First off… if you stack “if” statements like this, you get 2-to-the-number-of if statements paths. This block has 2^13, or 8192, paths through JUST IT. This is sort of modeling a switch statement, but it isn’t because it’s a fall thru not a single choice. And let’s ignore the use of 1 (a magic number) with no explanation of what it is, or why it should be 1 (I’ll cover magic numbers later).
Another risk here is that there will be just the right set of closing */ comment brackets, and you will end up with compiling code that you did not intend.
Commenting out code is a sign that a) you are hoping not thinking, b) you are not familiar with or using modern configuration management tools (like GIT or SVN), and that you have future plans for this code where it may be out of context from changes that happened while it was dormant.
I know everybody “does it”. I get that. The scope and scale of the use of commented-out code concerns me as a clear sign of poor development practices and inexperienced and/or untrained developers.
Floating Point Comparisons of Equality
Floating-point comparisons don’t always behave as you expect. Their behavior can also vary with compiler and build target options. These cause code comprehension and code portability issues, and bugs when the floating comparisons don’t act as you expect.
CodeCheck found 51 violations, 23 in the key simulation code. Many of them are in this variant:
double SomeVariable = 0.0
and then later…
if (SomeVariable == 0) {}
which does not concern me. This pattern may be problematic if targeting some exotic platform without the most modern compilers (clang, gcc, msvc), however, I do not envision this code being compiled in that type of system, so I’m not worried. Cleaning it up would be a good idea, but probably not an issue.
This, however, very well might be:

Here we have a calculated and passed in argument t (double) that is compared for equality versus another calculated double… it seems very likely that due to precision errors that this will not give the same results from run to run or especially from compiler to compiler/computer to computer.
This is at the heart of a loop inside the core covid simulation code and I’m pretty sure the results would not be predictable. This might be cleaned up by testing an error range. For instance to check if “t is in a .01 range of P.SD-CHangeTimes[ChangeTime]” might be better, but I don’t know the intent of this IF statement – so I’m not sure, except that this is probably is not behaving as they expected.
There were 9 patterns like this in the core covid simulation code. And one that bears further looks in the rand.cpp poisson distribution code:

Inspection of “beta“, which is a parameter to the function it is declared in (gen_gamma_mt), makes me suspect it is never, and can never be equal to 1, if just off floating-point precision errors. A typical way the parameter is passed in is:

Tracing back the source of P.InfectiousnessSD, it is the product of a series of floating-point and trigonometric operations and it seems unlikely that exactly 1 would be the result.
Functions Too Long (> 800 lines)
Long functions, that cross monitor boundaries are hard to understand and maintain. Generally, I limit this to 200 lines, which is about what I can see on a vertically mounted monitor.
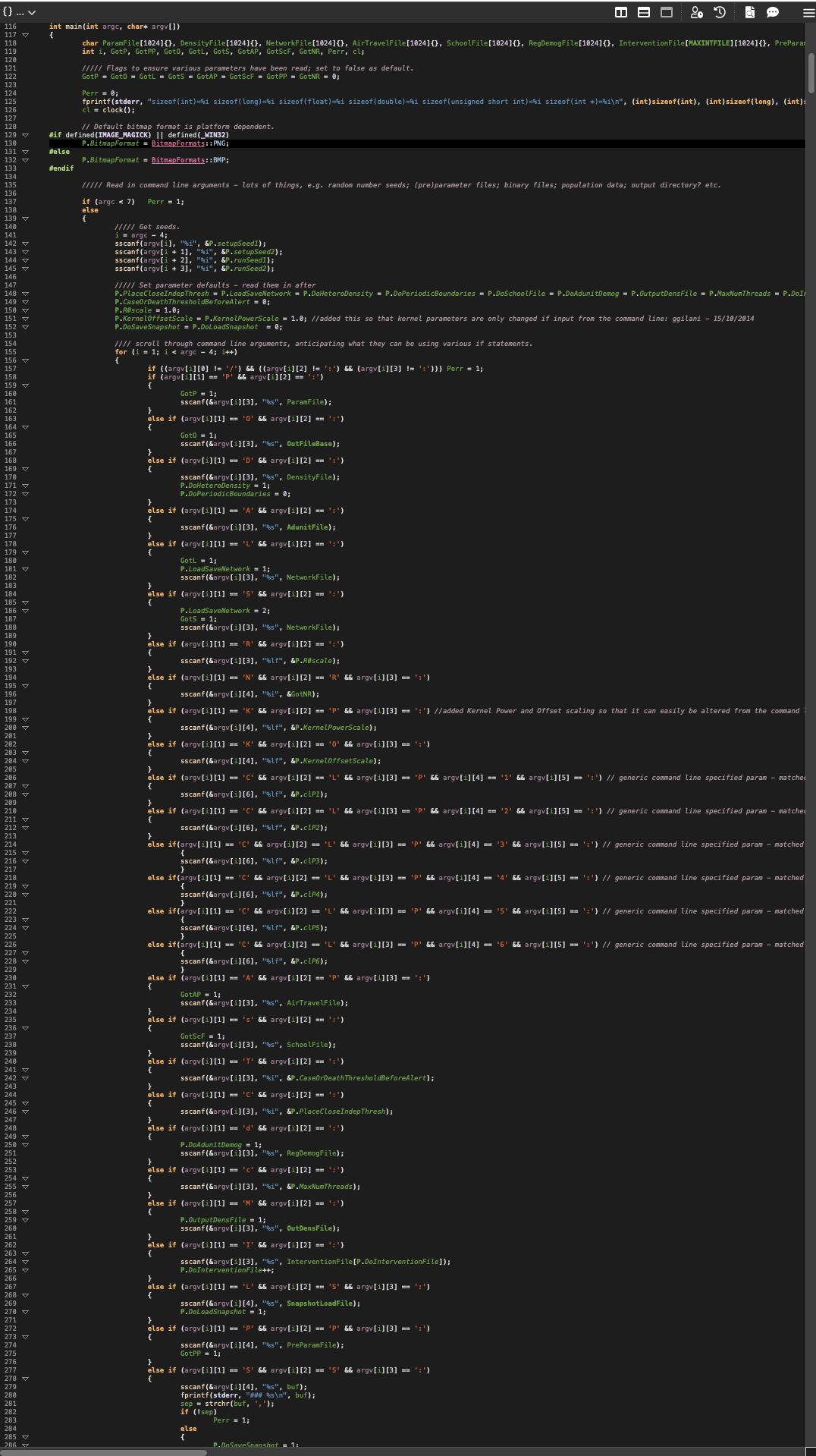
Which I consider generous, as it’s near impossible to track the 200(ish) lines shown here.
Why did I limit this check to 800 lines? Mainly because I just want to find really bad situations, not just “sorta bad”.
In total, we found 2 violations of the 800 line limit, and happily – just one in the core simulation code. It’s a doozy… function readParams has these stats:
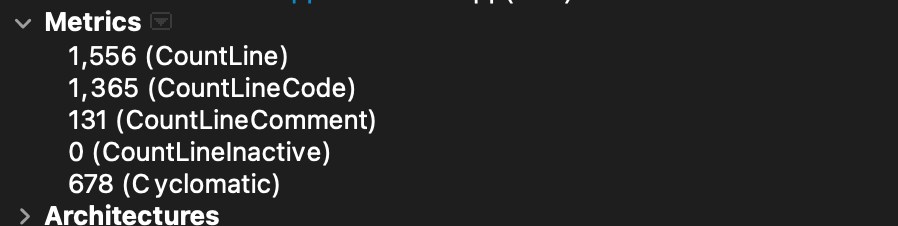
In doing this I actually found a bug in Understand in that it could not draw a flowchart of its logic – which means it’s really out there. I reported that to the team responsible for that part of Understand but we have not yet been able to draw it.
This is the part of the software which reads the parameters and sets the model up. I’d say it is very likely it has bugs and is likely unmaintainable.
As an aside, the normal convention for this metric is 200 lines of code in a function. When I set the check to that it finds 19 additional problematic functions.
To give you an idea of the issue here, check out this skeletonized control flow graph of the next biggest function (that Understand did draw):
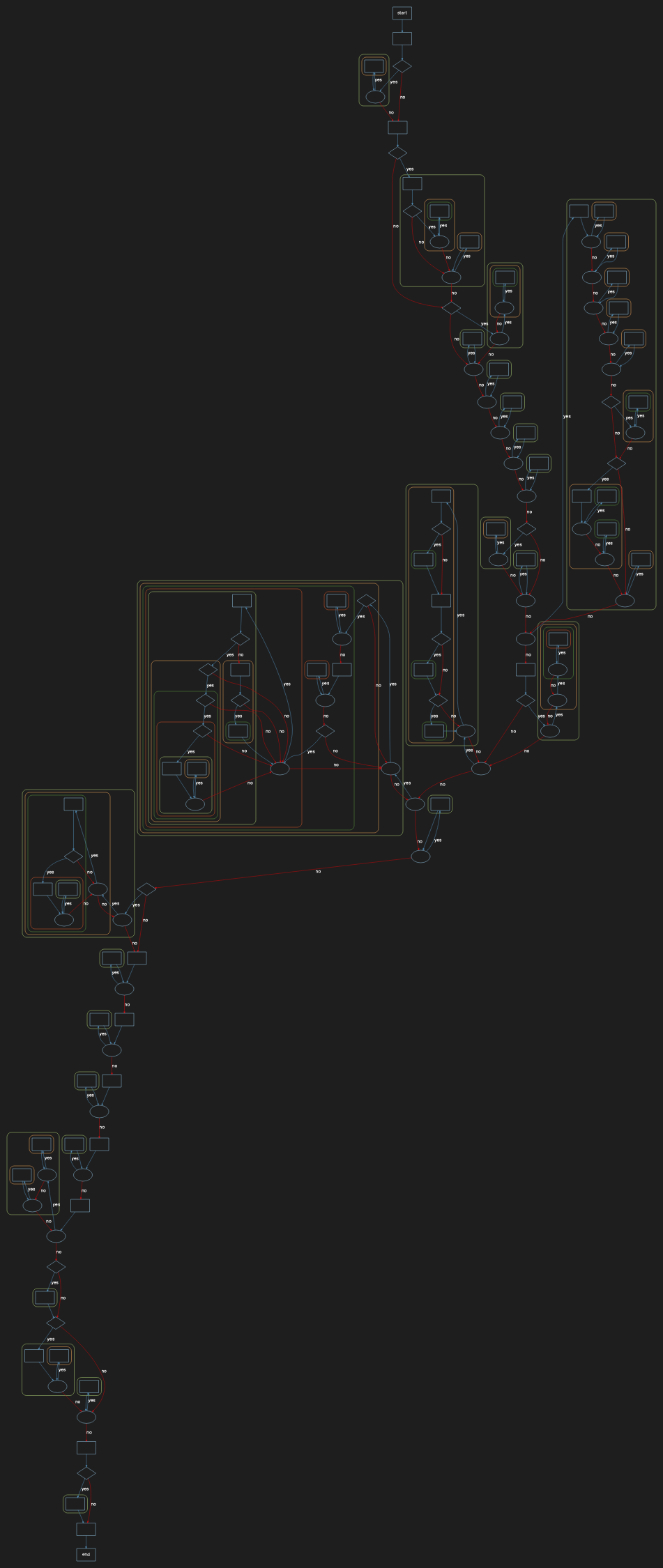
My best advice here is that while big functions can work, they are very difficult to change without causing bugs.
I’d recommend refactoring or rewriting using modern development principles before making changes to this code.
Goto Statements
Goto statements have a deservedly bad reputation stemming from the early days of C coding – where there was overlap with programmers who cut their teeth using assembly language.
I’ll admit… I’m one of them. I wrote my first program in 1976 and it used PLENTY of gotos. I even snorted when my professor at my first Intro to CS class in college said it was possible to write a program without GoTos using “structured” programming.
Well, I learned, quickly, and haven’t used one since except in short jaunts into assembly language for embedded projects.
In the modern world… they are not needed and they are a sign of poor programming practices, and if heavily used, as in one file of this project can make the code completely indecipherable and impossible to maintain.
There are 70 uses in this code, all in file “rand.cpp” and are stemming (I assume) from automatic translation from the original FORTRAN source code. Here’s an example:
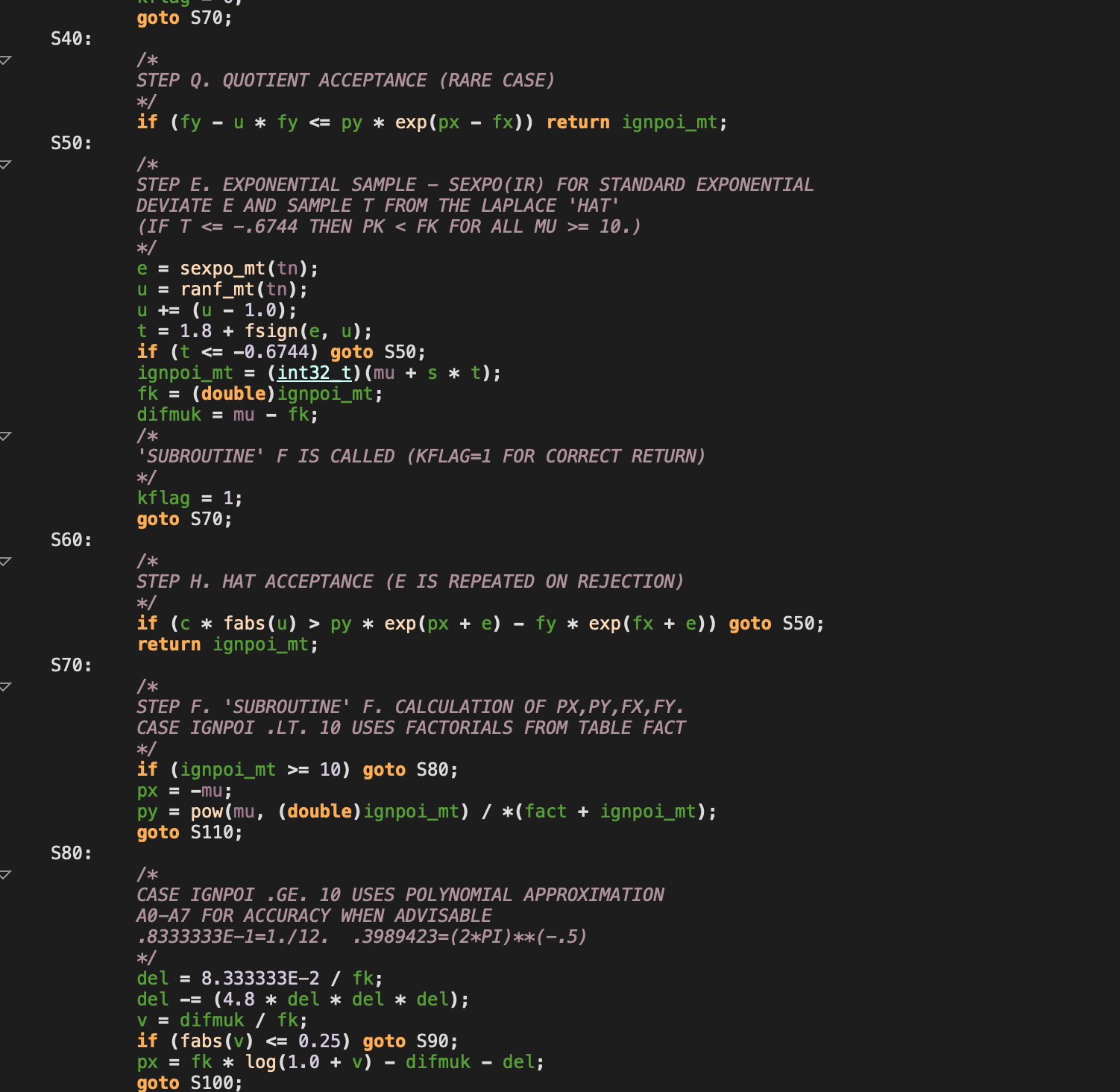
My assessment here is this code is completely unmodifiable and cannot be comprehended. It does what it does and probably no human knows what it does or could successfully modify it.
It is a random number generator and poisson distribution library and is at the core of what this simulation does. I suspect it is a commonly used library, which is probably solid… but how do we know? And who could fix it if it isn’t?
In a more perfect world, they would refactor this and use a more commonly used, modern, and more widely tested random number/poisson distribution library from Boost.
Magic Numbers
0, 1, 2, 8, 16, 32, 1 e10…. these are magic numbers. They are magic because they do something but you don’t know how or why.
Why was the number chosen? How often is it used? In general, it’s better to use a named thing like “FFT_FRAME_SIZE=1024”.
And… well, let’s get this out of the way… sometimes constants can be used to “fudge” answers towards a desired outcome. The use of odd, unnamed, constants in a simulation makes it less explainable and thus less believable.
This code had 724 uses of magic numbers.
Most of the 1, 0, -1 variety used for control points (set to 0, see if it’s still 0 as an if check). This form of deferred logic is hard to debug and can cause side effects. It is a bad practice, but at least is understandable.
Others belong to the efficient algorithm power of 2 – 2, 4, 16, 1024, 2048 category. Meh… Some algorithms work better along powers of 2. I get it. Make libraries/api out of those, don’t include them in the mainline of your code.
Others are related to image construction – for instance a 3000 pixel bitmap graphing simulation output. Sigh… it could be really simple to have MAX_PIXELS_HEIGHT and MAX_PIXELS_WIDTH.
Some that concern me are:

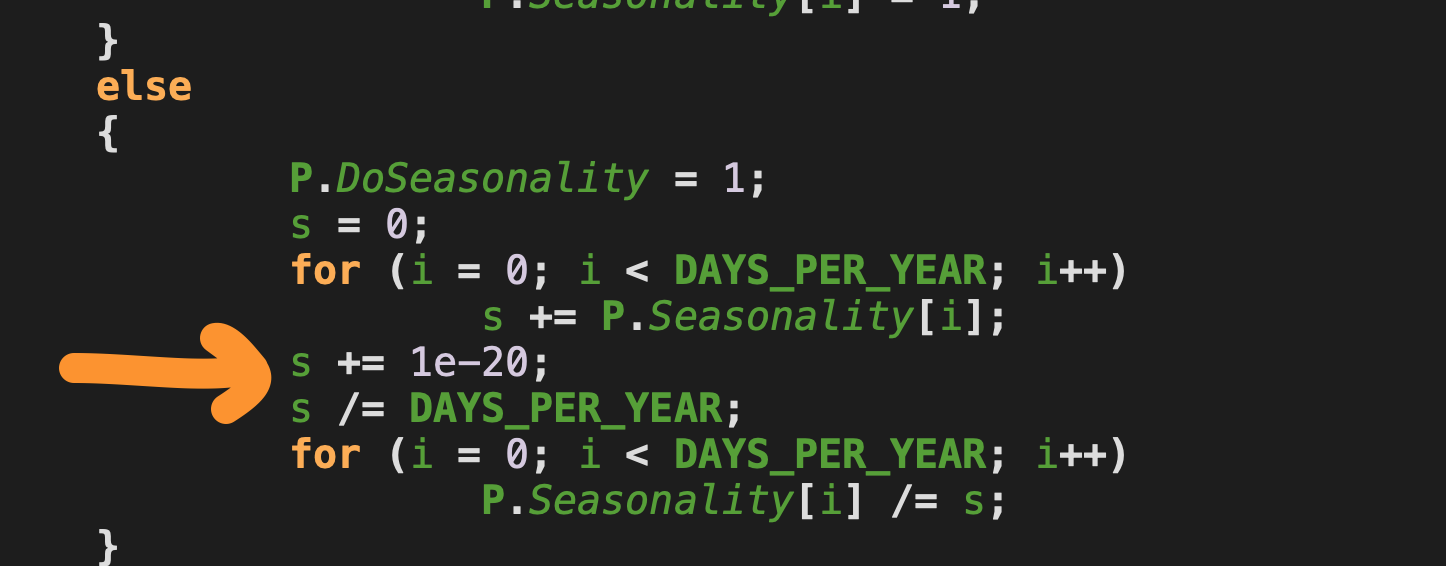

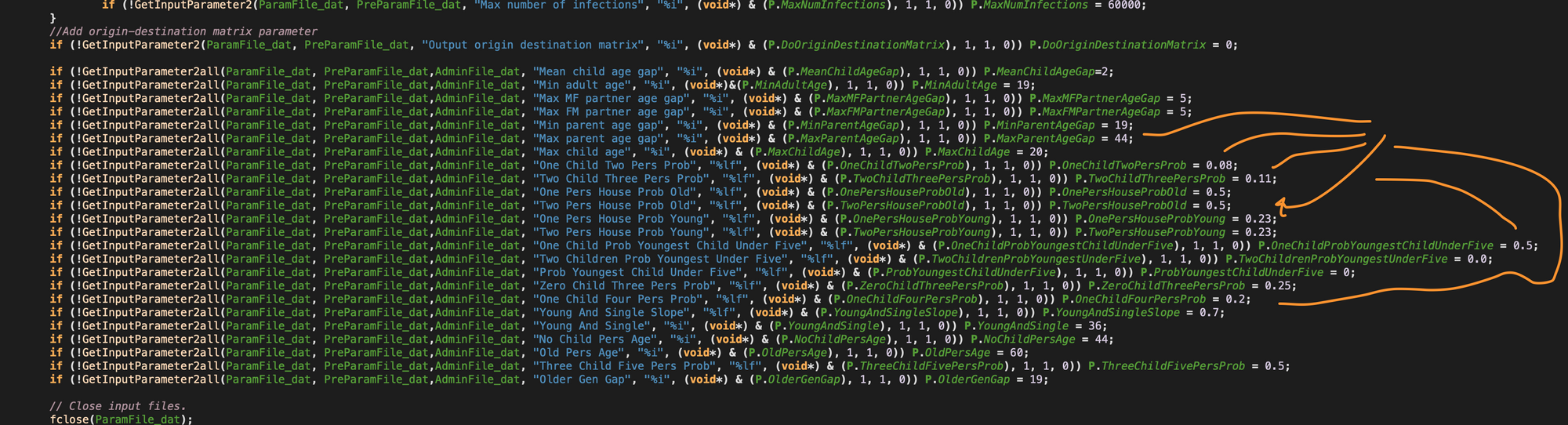
Anyway… clearly the authors of this code have an issue with describing the numbers they use in their model. One way to look at this is if I change one of these, what impact would it have on the model’s answer, and why is one magic # better than another?
A good first step would be to label them. For instance, if it’s reasonable that 44 years is the maximum age between children in a household – describe it as such and describe the source:
#define MaxGapBetweenChildren 44 // years, as defined from 2020 WHO stats (link)
That would help readers of the code have more faith, and modifiers of the code know what to do to update these stats should they change.
Overly Complex Functions
We covered long functions earlier. You can, however, have short and unmaintainable functions. You can find those by looking at Cyclomatic Complexity.
Cyclomatic Complexity is a measure of the minimum number of choices (or paths) to recreate all the logic in a function. See (https://en.wikipedia.org/wiki/Cyclomatic_complexity) for more information.
How many things can you keep track of in your head? If you are a normal human, somewhere in the range of 7 to 10 things. Hence a typical desired maximum for this is 10. I set this to 20, just to find truly problematic functions.
There were 30 functions with Cyclomatic Complexity over 20, with the highest being function “ReadParams” in covidsim.cpp with an astounding complexity of 678. This is that function we couldn’t draw a control flow of earlier. It’s a doozy.
The Understand metrics browser shows its path count (logical paths thru the code) as 999,999,999 – which is basically the highest number we report. It’s quite likely in the trillions. It has 69 “knots” – or overlapping logical jumps. These are super hard to debug/understand.
Reading in parameters might not seem like a critical item. However, these are the parameters that control the model – bugs here have big effects downstream.
And there are bugs. There have to be. It is simply too complicated, too “thorny” and too big for there not to be. Here’s what its UML Sequence Diagram looks like:

ReadParams is excessive. There are other functions of interest, which I can identify using Understand’s Entity Locator browser, sorting by “Cyclomatic”:
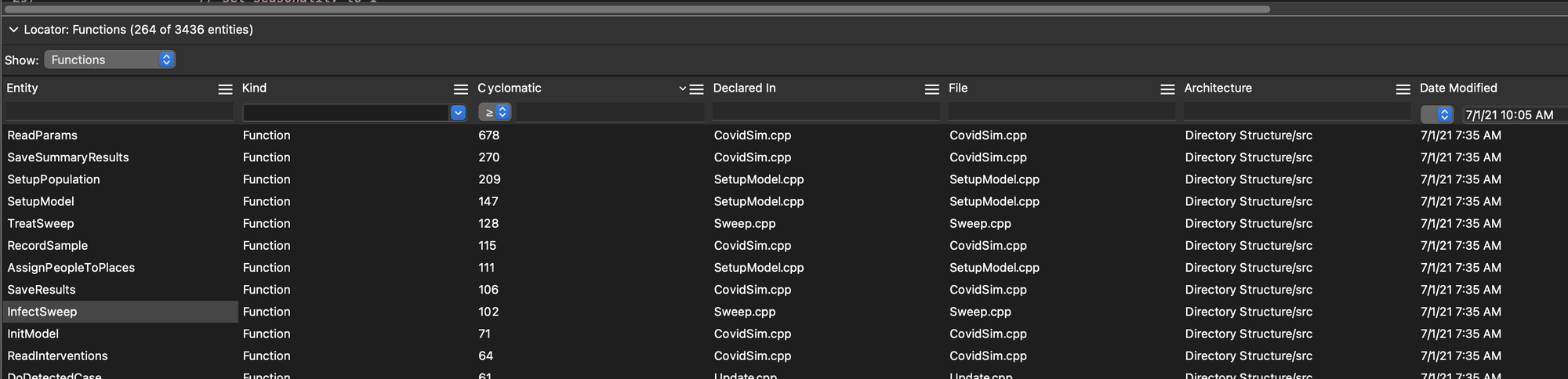
Using the Entity Locator I hunted for a complex function in the core model source and found “InfectSweep”, which is the workhorse of the simulation:

Examining it, we see its complexity is 102, and its path count that 999,999,999 number – so more than a billion paths.
Here’s its control flow logic:

There are bugs in here. We don’t know what they are, but they are there. And changes, considering the sheer number of decisions and paths will introduce more.
The function is unmaintainable and should be refactored and re-written.
Summary
Covid-Simulation is not the worst code I’ve ever examined. That distinction lies in some customer code were a long since departed engineer had used the C pre-processor to make C look as much like Pascal as possible. And then broke a bunch of other good practices.
But maybe, other than the software on a plane I’m flying in, it is the most important software I’ve ever examined.
I don’t doubt the goodwill and intent of those who wrote it. What I strongly urge is that they rewrite it – and mix their knowledge of epidemiology with a strong team of experienced scientific programmers and that this work be done in open source, in public, and with the encouragement of external source and operational review.
Title Photo by Fusion Medical Animation on Unsplash





