

Abstract: revisiting how we detect and report duplicate lines of code, and creating a plugin metric to report it.
If you asked how to find duplicated lines of code with Understand, you were probably directed to this Perl interactive report plugin. So, if a solution has been hanging around for this long, why revisit it now?
The interactive report lists all the duplications. But what if I want to know the file with the most duplicated lines. Then I need a duplicated lines metric, like CBRI Insight. So, that means I’ll be writing a duplicated lines of code metric plugin.
Perl Duplicate Lines of Code Detection
I’d rather avoid reinventing the wheel, so the first step is to understand how the Perl interactive report works. The metric plugin has to be written in Python so using the Perl code directly is not an option.
Actually, the Perl version I examined was for CBRI Insight since I was looking at all the metrics in the plugin. I’m not great at Perl, but here’s the outline I got from the script:
- Create an index from a region of code (N lines long) to the file and line number for every file. Each region of code is processed according to the report options for stripping whitespace and comments.
- Create a list of possible matches from every index entry that had more than one location.
- Ensure each location occurs in only one match. So, if 6 lines are duplicated and the window was 5 lines big, then there would be two index entries, one for the first five lines and one for the last five lines. This step seems to be intended to remove the second index entry from the list of possible matches.
- Grow each remaining match. Add another line to the match object while the text at all locations continues to match. Text at locations is found by opening the file(s) again.
- CBRI Insight additionally calculates the lines for each file by summing the length of every match the file is involved in.
Sample Code
So far so good. But step 5 made me wonder what happens if the same line belonged to multiple match objects. Would the line get counted twice? I’ll create some sample code and see what happens.

As a human looking at the code, I’d expect to see two match objects, one with the framed purple boxes and a second with the shaded purple boxes. The total number of duplicated lines would be 21.
Here’s what CBRI Insight reports:
6 useful lines duplicated in 2 locations
setrefgraph/duplicates.cpp(13)
setrefgraph/duplicates.cpp(22)
5 useful lines duplicated in 3 locations
setrefgraph/duplicates.cpp(5)
setrefgraph/duplicates.cpp(12)
setrefgraph/duplicates.cpp(21)
The matches are pretty close to expected. The only difference is that the shaded purple boxes are one shorter, starting at lines 13 and 22 instead of 12 and 21.
However, the total number of duplicated lines is wrong. The formula does double count lines in the overlapping region (6 * 2 + 5 * 3 = 27).
Snowballing
Getting the duplicated lines metric without double counting lines seems straightforward. It doesn’t even need steps 3-5. For each potential match, add each location to a set to ensure its unique and then find the size of the set.
However, as a user, I’d want to be able to get from the duplicated line count to a view of the duplicated lines. So, my metric plugin needs to agree with the other views of duplicated lines in Understand.
Then, I also need to check the original Perl interactive report (since I’ve been looking at the CBRI Insight version) and I need to check the relatively new CodeCheck check. As a bonus, if the CodeCheck has the information I need, then the metric can be calculated from the CodeCheck results to avoid running the duplicate code detection more than once.
Unfortunately, the original Perl script reported only a single match that doesn’t correspond to either of the expected matches and the CodeCheck script didn’t find any matches.
[-] 5 lines matched in 2 locations
setrefgraph/duplicates.cpp(5)
setrefgraph/duplicates.cpp(21)
[-] View Duplicate Lines
if (val1 == 0) {
calc += val2;
calc *= val3;
calc -= val2;
calc += val3
The New Problem
So, even though calculating the metric only requires steps one and two, I’m going to need to also implement steps 3 and 4 to create an interactive report and a CodeCheck so all three are consistent.
At this point, it’s worth taking a step back to consider whether there are better ways of detecting duplicate code. To summarize a search in that area, it turns out there are lots of different types of duplicate code, from exact copies, to copies with insertions or deletions, to copies with name changes and order changes. Since I’m not a patent lawyer, I’ll stay close to the original approach.
However, I’d like to avoid reading the file twice and I want to support multiple matches starting at the same location like my sample code. So, I’m going to modify the original algorithm to be a little closer to a genome assembly algorithm and track what the next node is. So the sample code would form this graph with a window of 5 lines and showing only nodes and edges with at least two locations:

Each node is still an initial match. In addition, any edge with at least two locations but whose number of locations does not match both nodes, is also a match. So the first edge in the diagram is also a match. Then, instead of extending matches by re-opening the file, adjacent matches are merged together as long as the number of locations is identical. So, the final result is the two desired matches:

Final Results
The plugins can be downloaded from our plugin repository. They all rely on a central file, duplicates.py. So it’s best to download the whole folder. Furthermore, to be as consistent as possible, the ireport and CodeCheck both save data that the metrics plugin can read. So, if CodeCheck is run, then the metrics will be calculated from the same results as CodeCheck was. If neither CodeCheck nor the IReport is run, then default option values for the number of lines, ignoring whitespace, and ignoring comments are used by the metrics.
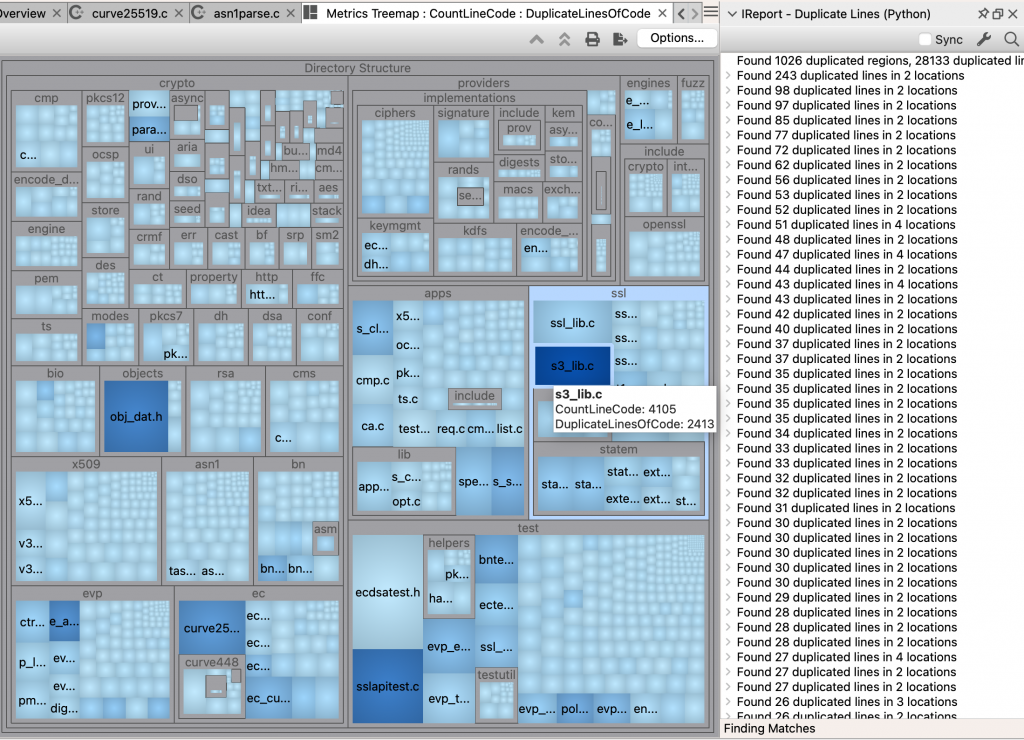
The file preprocessing code is separate from the match code. So, future work could ignore useless lines of code like CBRI Insight or replace names to detect copies with renames. We’d love to hear from you about what you’d like to see.





