

Abstract: The origin of the Blame margin in Understand.
I’ve always thought that “git blame” sounded a little mean. Was the purpose of the command to accuse people? Actually, a blame shows the last commit that changed a given line.
Personally, I rarely use blame to accuse people. Accusing the programmers who have been around longer than me doesn’t usually work out very well. And, most of the time I’m looking at the blame to understand the code rather than to fix a bug. The last commit to touch a line is often more useful than a comment. At least, my comments tend to read more like section headers (“populate table” followed by 3-20 lines of code). My commit messages are things like “Fix macro display in compare entities. Internal: issue #2082”. So a comment tends to tell me what the code is doing whereas the commit message tends to explain why the code is needed.
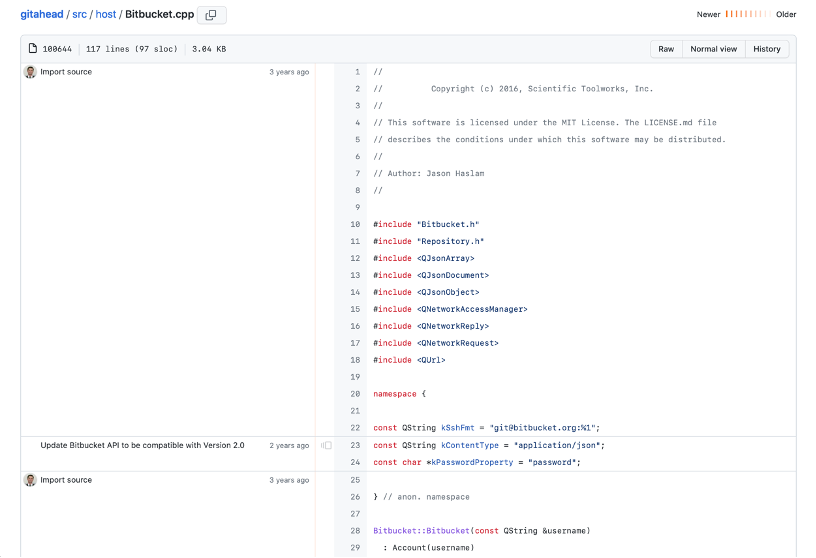
Given the usefulness of blames, the next question is how to display them. What immediately comes to my mind is how I’ve seen them on GitHub:
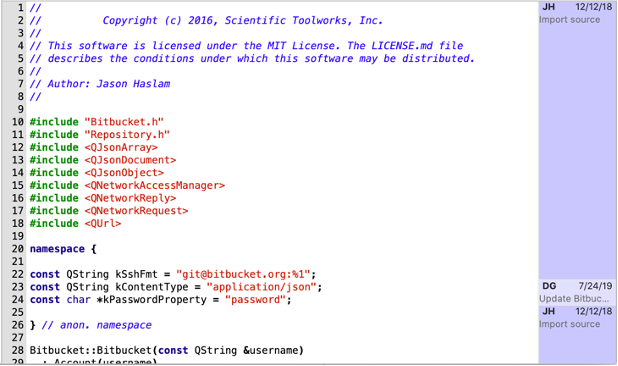
There’s also our open-source tool GitAhead:
And Visual Studio Code:
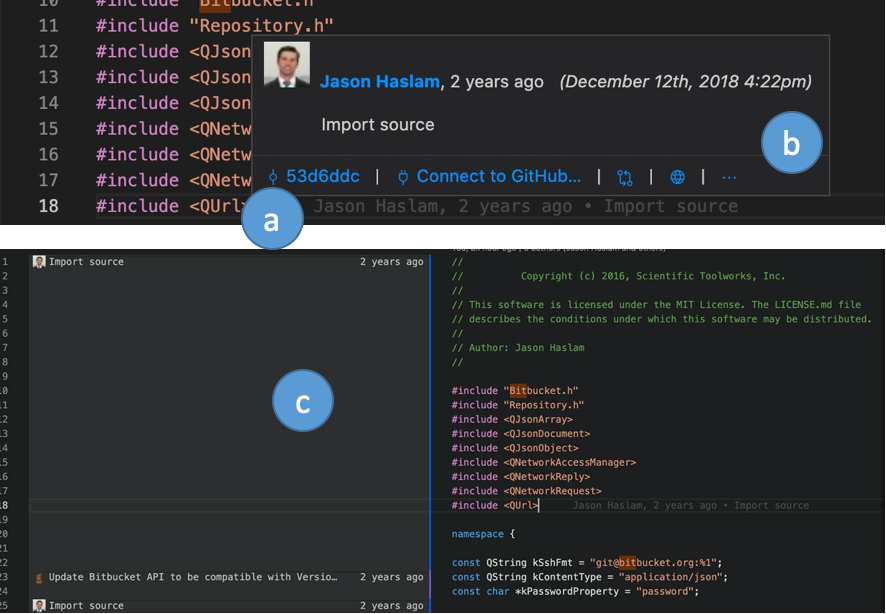
The common theme involves splitting the editor with text on one side and the blame information on the other side. My personal grievance with most of the views is how much (non-resizable) space the blame information takes. It’s too much space for an always-on feature.
So, for Understand, we decided to show the blame as a margin. That puts it on the left side of the view and gives it a defined width. The width is two characters, allowing for initials. It’s not resizable, but at least it’s small. Additional information is provided by hovering:
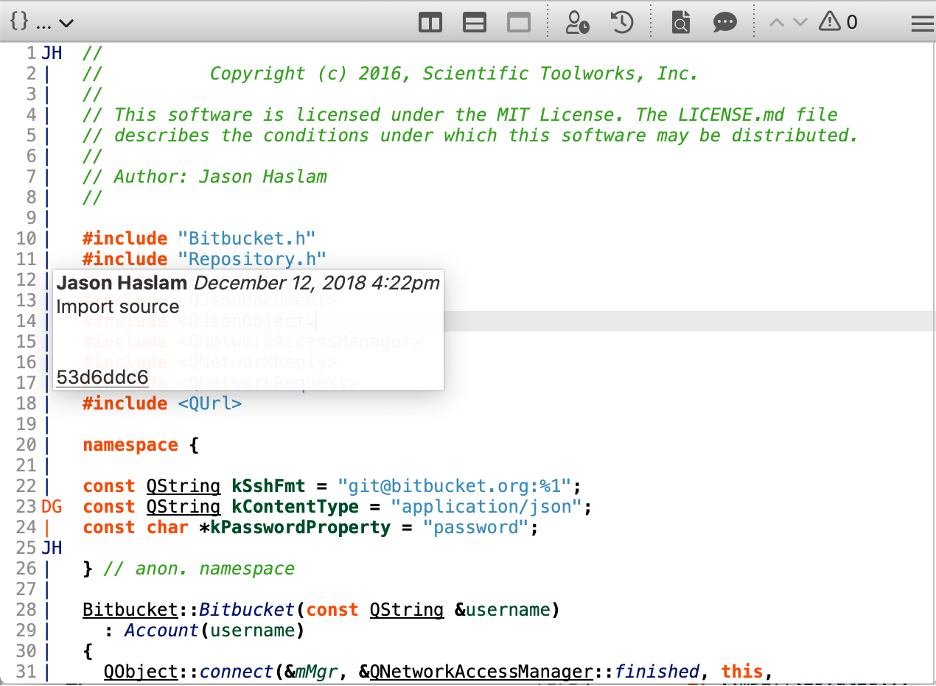
Now for the fun part. What happens when you start actively editing this file? Understand uses a wrapper library around libgit2 for Git access. The wrapper library is from the open-source project GitAhead also developed at Scitools.
Calculating a blame ultimately uses the libgit2 function git_blame_file. That calculates the blame given the state of the file at the provided commit (or HEAD if no commit is given).
If the current state of the file is not the same as the state of the file git used, then the blame needs to be updated. Libgit2 has a function git_blame_buffer. Given a reference blame and the new contents, it returns a new blame.
Lesson 1: Don’t use the blame returned from git_blame_buffer as the input to a second git_blame_buffer. Suppose you had the following three lines of code:
// Commit A
// Commit B
// Commit CNow, in the editor, you delete the second line. Since the editor is now different than the file contents used for the blame, you call git_blame_buffer. Now you have:
// Commit A
// Commit CSuppose you undo the change. The lines in the file are back to:
// Commit A
// Commit B
// Commit CBut if you call git_blame_buffer with the updated blame, the blame has:
// Commit A
// Null Commit (uncommitted changes)
// Commit C
Why? Because the information that line two came from commit B was removed in the first update.
Lesson 2: Library code might need patching. After fixing my re-use of updated blames, I hoped all the oddities I was seeing when updating blames would be fixed. Alas, there was still a problem: updating the text was introducing gaps in the blame.
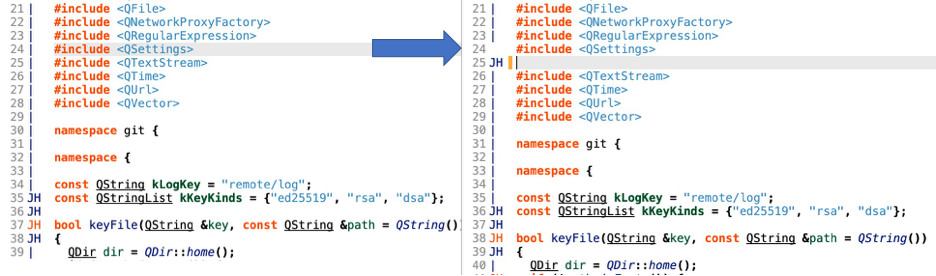
Why was updating causing a gap in the blame? It turns out this fix required a patch to the fork of libgit2 that we were using.
Step one to fixing the bug is understanding what’s going wrong. A good place to start is looking at the git_blame_buffer function.
int git_blame_buffer(
git_blame **out,
git_blame *reference,
const char *buffer,
size_t buffer_len)
{
git_blame *blame;
git_diff_options diffopts = GIT_DIFF_OPTIONS_INIT;
size_t i;
git_blame_hunk *hunk;
diffopts.context_lines = 0;
GIT_ASSERT_ARG(out);
GIT_ASSERT_ARG(reference);
GIT_ASSERT_ARG(buffer && buffer_len);
blame = git_blame__alloc(reference->repository, reference->options, reference->path);
GIT_ERROR_CHECK_ALLOC(blame);
/* Duplicate all of the hunk structures in the reference blame */
git_vector_foreach(&reference->hunks, i, hunk) {
git_blame_hunk *h = dup_hunk(hunk);
GIT_ERROR_CHECK_ALLOC(h);
git_vector_insert(&blame->hunks, h);
}
/* Diff to the reference blob */
git_diff_blob_to_buffer(reference->final_blob, blame->path,
buffer, buffer_len, blame->path, &diffopts,
NULL, NULL, buffer_hunk_cb, buffer_line_cb, blame);
*out = blame;
return 0;
}Essentially, the function is copying the blame and then running a diff. The updates to the blame happen in the callback functions passed to git_diff_blob_to_buffer: buffer_hunk_cb and buffer_line_cb. The first callback, buffer_hunk_cb is called for each diff hunk. A diff hunk describes a range of modified lines with the start line and line count in the first file and the start line and line count in the second file. The callback looks like this:
static int buffer_hunk_cb(
const git_diff_delta *delta,
const git_diff_hunk *hunk,
void *payload)
{
git_blame *blame = (git_blame*)payload;
uint32_t wedge_line;
GIT_UNUSED(delta);
wedge_line = (hunk->old_lines == 0) ? hunk->new_start : hunk->old_start;
blame->current_diff_line = wedge_line;
blame->current_hunk = (git_blame_hunk*)git_blame_get_hunk_byline(blame, wedge_line);
if (!blame->current_hunk) {
/* Line added at the end of the file */
blame->current_hunk = new_hunk(wedge_line, 0, wedge_line, blame->path);
GIT_ERROR_CHECK_ALLOC(blame->current_hunk);
git_vector_insert(&blame->hunks, blame->current_hunk);
} else if (!hunk_starts_at_or_after_line(blame->current_hunk, wedge_line)){
/* If this hunk doesn't start between existing hunks, split a hunk up so it does */
blame->current_hunk = split_hunk_in_vector(&blame->hunks, blame->current_hunk,
wedge_line - blame->current_hunk->orig_start_line_number, true);
GIT_ERROR_CHECK_ALLOC(blame->current_hunk);
}
return 0;
}
Looking at the code, wedge_line seems to be the line in the blame. If that line is past the end of the blame, then a new blame hunk (set of lines) is added. If the line is in the middle of a range, then the hunk (set of lines) is split. So, the callback ensures that any changes are happening at the edges of a valid hunk instead of in the middle.
For the example in the picture, a line was inserted at 25 (1 based indexing). So, for the diff hunk:
- old_start = 24
- old_lines = 0
- new_start = 25
- new_lines = 1
Since old_lines is 0, the wedge_line (and current_diff_line in the blame) will be 25, the new start. The first few blame hunks in the blame are:
| Hunk | (Final) Start Line | Line Count |
| A | 1 | 14 |
| B | 15 | 4 |
| C | 19 | 1 |
| D | 20 | 15 |
| E | 35 | 1 |
| F | 36 | 1 |
| G | 37 | 1 |
Line 25 falls in the middle of the fourth blame hunk (labeled D in the table). So, the blame hunk will be split. The wedge line – the original start line number (21) gives the offset to split around: 4. So the new list of hunks will be:
| Hunk | Start Line | Line Count |
| A | 1 | 14 |
| B | 15 | 4 |
| C | 19 | 1 |
| D1 | 20 | 4 |
| D2 | 24 | 11 |
| E | 35 | 1 |
| F | 36 | 1 |
| G | 37 | 1 |
Now the line callback will be called for each line in the hunk. There is only one line in this diff hunk: the inserted line. The diff_line has the following values:
- origin = “+”
- old_lineno = -1
- new_lineno = 25
- num_lines = 1
The line callback is:
static int buffer_line_cb(
const git_diff_delta *delta,
const git_diff_hunk *hunk,
const git_diff_line *line,
void *payload)
{
git_blame *blame = (git_blame*)payload;
GIT_UNUSED(delta);
GIT_UNUSED(hunk);
GIT_UNUSED(line);
if (line->origin == GIT_DIFF_LINE_ADDITION) {
if (hunk_is_bufferblame(blame->current_hunk) &&
hunk_ends_at_or_before_line(blame->current_hunk, blame->current_diff_line)) {
/* Append to the current buffer-blame hunk */
blame->current_hunk->lines_in_hunk++;
shift_hunks_by(&blame->hunks, blame->current_diff_line+1, 1);
} else {
/* Create a new buffer-blame hunk with this line */
shift_hunks_by(&blame->hunks, blame->current_diff_line, 1);
blame->current_hunk = new_hunk(blame->current_diff_line, 1, 0, blame->path);
GIT_ERROR_CHECK_ALLOC(blame->current_hunk);
git_vector_insert_sorted(&blame->hunks, blame->current_hunk, NULL);
}
blame->current_diff_line++;
}
if (line->origin == GIT_DIFF_LINE_DELETION) {
/* Trim the line from the current hunk; remove it if it's now empty */
size_t shift_base = blame->current_diff_line + blame->current_hunk->lines_in_hunk+1;
if (--(blame->current_hunk->lines_in_hunk) == 0) {
size_t i;
shift_base--;
if (!git_vector_search2(&i, &blame->hunks, ptrs_equal_cmp, blame->current_hunk)) {
git_vector_remove(&blame->hunks, i);
free_hunk(blame->current_hunk);
blame->current_hunk = (git_blame_hunk*)git_blame_get_hunk_byindex(blame, (uint32_t)i);
}
}
shift_hunks_by(&blame->hunks, shift_base, -1);
}
return 0;
}
Since the line origin is an addition, control goes into the first if statement. The current_diff_line is the wedge_line, so line 25. The current hunk is the new hunk D2 (start line 24, line count 11). The hunk does not end at or before line 25, so the else statement runs. The shift_hunks_by call starts with the hunk containing the line and adjusts its start line and all the following hunks start lines. So, the blame hunks now look like this:
| Hunk | Start Line | Line Count |
| A | 1 | 14 |
| B | 15 | 4 |
| C | 19 | 1 |
| D1 | 20 | 4 |
| D2 | 25 | 11 |
| E | 36 | 1 |
| F | 37 | 1 |
| G | 38 | 1 |
Finally, a new hunk for the inserted line is created, labeled D* in the table. Its start line is the current_diff_line (25) and it has a line count of 1.
| Hunk | Start Line | Line Count |
| A | 1 | 14 |
| B | 15 | 4 |
| C | 19 | 1 |
| D1 | 20 | 4 |
| D* | 25 | 1 |
| D2 | 25 | 11 |
| E | 36 | 1 |
| F | 37 | 1 |
| G | 38 | 1 |
The problem, looking at the final hunks, is that line 24 doesn’t belong to a hunk anymore, because D* starts at line 25 instead of line 24. That’s where the gap comes from.
Fixing this ultimately required updating our fork of the libgit2 library with the following patch.
--- a/src/blame.c
+++ b/src/blame.c
@@ -432,7 +432,7 @@ static int buffer_hunk_cb(
GIT_UNUSED(delta);
- wedge_line = (hunk->old_lines == 0) ? hunk->new_start : hunk->old_start;
+ wedge_line = hunk->new_start + (hunk->new_lines == 0 ? 1 : 0);
blame->current_diff_line = wedge_line;
blame->current_hunk = (git_blame_hunk*)git_blame_get_hunk_byline(blame, wedge_line);
@@ -445,7 +445,7 @@ static int buffer_hunk_cb(
} else if (!hunk_starts_at_or_after_line(blame->current_hunk, wedge_line)){
/* If this hunk doesn't start between existing hunks, split a hunk up so it does */
blame->current_hunk = split_hunk_in_vector(&blame->hunks, blame->current_hunk,
- wedge_line - blame->current_hunk->orig_start_line_number, true);
+ wedge_line - blame->current_hunk->final_start_line_number, true);
GIT_ERROR_CHECK_ALLOC(blame->current_hunk);
}
@@ -469,8 +469,9 @@ static int buffer_line_cb(
if (hunk_is_bufferblame(blame->current_hunk) &&
hunk_ends_at_or_before_line(blame->current_hunk, blame->current_diff_line)) {
/* Append to the current buffer-blame hunk */
+ shift_hunks_by(&blame->hunks, blame->current_hunk->final_start_line_number +
+ blame->current_hunk->lines_in_hunk, 1);
blame->current_hunk->lines_in_hunk++;
- shift_hunks_by(&blame->hunks, blame->current_diff_line+1, 1);
} else {
/* Create a new buffer-blame hunk with this line */
shift_hunks_by(&blame->hunks, blame->current_diff_line, 1);
@@ -484,11 +485,11 @@ static int buffer_line_cb(
if (line->origin == GIT_DIFF_LINE_DELETION) {
/* Trim the line from the current hunk; remove it if it's now empty */
- size_t shift_base = blame->current_diff_line + blame->current_hunk->lines_in_hunk+1;
+ size_t shift_base = blame->current_hunk->final_start_line_number +
+ blame->current_hunk->lines_in_hunk;
if (--(blame->current_hunk->lines_in_hunk) == 0) {
size_t i;
- shift_base--;
if (!git_vector_search2(&i, &blame->hunks, ptrs_equal_cmp, blame->current_hunk)) {
git_vector_remove(&blame->hunks, i);
free_hunk(blame->current_hunk);The first change always uses the new_start for the wedge_line. That change fixed cases with multiple diff hunks because in later diff hunks old_start no longer corresponded to the current state of the blame. The second change similarly changes the old_start_line_number to final_start_line_number so that it corresponds to the middle-of-update state of the blame instead of the original blame.
For the line callback, the changes are mostly ordering. Shift the hunks after this hunk before updating the current hunk so that the current hunk is not shifted. With the original order, the current hunk contains the line so it is shifted as well, leaving a gap. Similarly, with deletion, start with a line belonging to the following hunk.
With that patch, the blame margin in Understand doesn’t get gaps anymore.
Lesson 3: remember filters. The changes so far worked great on my Mac. Unfortunately, a Windows user found that the blame always showed everything as uncommitted changes. The git repository changed newlines on commit (autocrlf), so the buffer in the Understand editor did not match the file stored in Git and every line was reported as different. To fix this, the buffer from the editor needs the filters applied to it that Git would apply when committing the file. To fix this, I modified the wrapper library:
-Blame Blame::updated(const QByteArray &buffer) const
+Blame Blame::updated(const QByteArray &buffer, const FilterList & filters) const
{
git_blame *blame = nullptr;
- git_blame_buffer(&blame, d.data(), buffer, buffer.length());
+ QByteArray result = buffer;
+ if (filters.isValid()) {
+ git_buf raw = GIT_BUF_INIT_CONST(buffer.constData(), buffer.length());
+ git_buf out = GIT_BUF_INIT_CONST(nullptr, 0);
+ git_filter_list_apply_to_data(&out, filters, &raw);
+ git_buf_dispose(&raw);
+ result = QByteArray(out.ptr, out.size);
+ git_buf_dispose(&out);
+ }
+
+ git_blame_buffer(&blame, d.data(), result, result.length());
return Blame(blame, repo);
}
So, if you’re ever writing your own blame margin, (1) always update against the original blame, (2) you might have to patch libgit2 to avoid gaps, and (3) don’t forget to apply git filters to the buffer before using it for updating.





