

Abstract: Understand is used to determine how much work it would take to create a database that reads files from a git repository.
One of the larger additions to Understand since 6.0 was released is git integration.
A separate feature set is comparison databases.
The next logical step for git integration and comparison databases is using git to create a comparison database. Wouldn’t it be convenient if, instead of checking out another copy of the source tree, Understand could read the files directly from git?
The good news is that most of the file reading is already centralized. The problem is that word “most”. How much work is it really?
The central interface for file reading is in readfile.h which defines a class “Readfile::File” with three possible constructors.
- File(); // Construct an invalid File.
- File(QString name,Udb::Db * =0);
- File(Kind,Udb::Db *,const std::string &);
If the interface is going to work with git files, then the provided database object (Udb::Db*) cannot be null because the git settings are retrieved through the database object. So, constructors two and three could be a problem if the database pointer passed to them is null. The information browser is a fast way to check all the calls. I use it with the previewer to avoid opening a lot of extra editor windows.
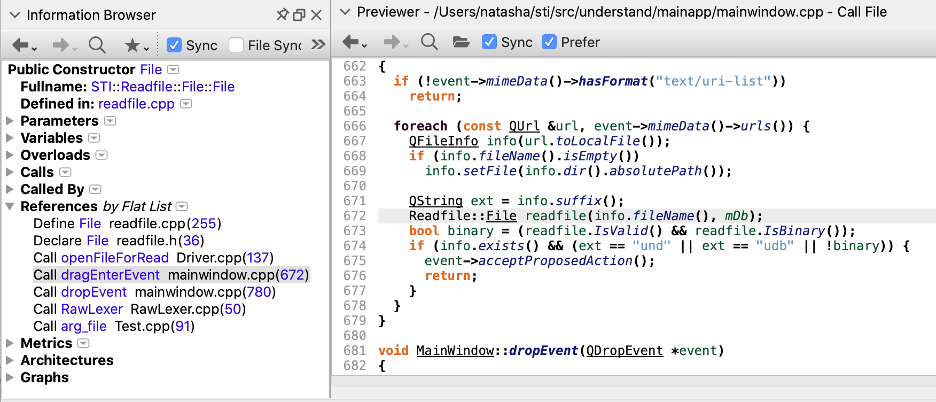
Of constructor two’s call references, only the first and last don’t provide a database. The last one, in Test.cpp, is not an immediate problem since the test doesn’t use a database. The first one is a problem. Driver.cpp is part of the C++ strict parser. So, that’s one major client that would have to be updated.
The second constructor is easier to visualize with a called-by tree:
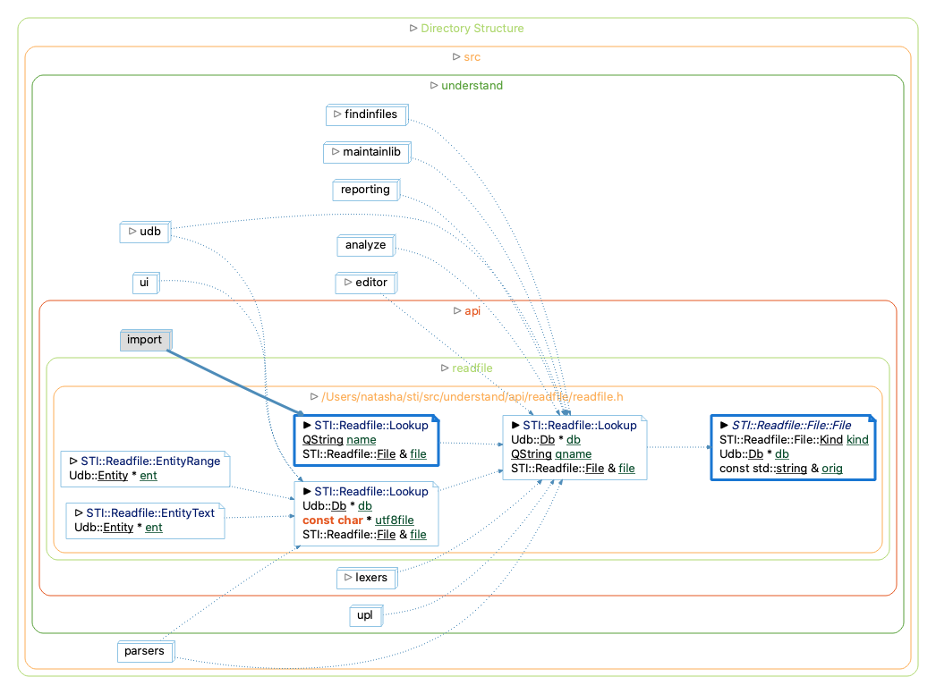
A few fun facts about getting this graph. The default graph variant is the simplified variant, which lets you change options directly on nodes but doesn’t have clusters. I wanted clusters because I’m interested in the major areas of the code that use ReadFile, so I switched the variant to Cluster. I also start with the level at 1 so the graph doesn’t explode. I can use the arrows to extend the graph. Since the constructor is only called by one function (Lookup), I expand that function, and its two overloads. To help distinguish the overloads, I use the right click menu to set the “Parameters” option to “On.”
Now, interpreting the graph. I don’t need to worry about any calls into EntityRange or EntityText because the database is accessible from the entity. But one of the Lookup overloads looks problematic because it doesn’t require a database. I’ve highlighted edges into that overload in the graph to quickly find problematic libraries. There’s only one. Yay! But the one library is the import library which reads visual studio project files, xcode project files, and CMake compile command json files. So, it does need to be updated to provide the database. A quick screening through the references on the other lookup functions reveals only one other null database, from an extension parser plugin. While that will need to be fixed eventually, it doesn’t impact most users.
So, a first pass screening with Understand shows that implementing this feature will require updating two major parts of the code: the import library and the strict parser. Are those easy to update? It turns out they are not. Neither of those callers has access to the database at all. But, is the overall goal feasible? Yes. Even without updating those clients, it looks like watched directory projects using the fuzzy c++ parser will work just by updating Readfile.





