

TL;DR
I was curious about how complicated my whole project was, so I wrote a Python script that uses the Understand API to calculate it.
Details
Cyclomatic Complexity is defined as “the number of linearly independent paths through a program’s source code”. In practice, this is usually calculated and used at the function/method level, and that’s how Understand calculates it as well. However, I was feeling curious and decided I wanted to find out the true complexity of my code. How many independent paths are there through my entire project?
Understand offers metrics that can show you the average complexity for all nested functions, the maximum complexity of these nested functions, and even the total sum of their complexities. While these metrics have their own use cases where they are certainly helpful, none of them show the true complexity of your project. To find this, we’re going to want to multiply our complexities as we walk down the call tree for our root function instead of summing them.
Why multiply them? Well, the paths in your program permutate, and cyclomatic complexity represents a subset of paths needed to recreate all the decisions in a function. So, to accurately capture all possible decisions branching out along the call tree, we need to multiply the complexities at each node along that tree.
Luckily, this isn’t too hard to do ourselves with a script we’ll write using the Python API. We can then run the script from the command line and print out a clean summary of the complexity of our entity.
Note: If this is your first time using the API to write a script, consider going through this support article before continuing!
Let’s start by importing the necessary modules and packages:
import understand
import re
import sysWe’re importing ‘sys’ as a way to manually set Python’s recursion limit higher than the default. Now we can set that limit and define our helper function that recursively walks the call tree:
# modify the default recursion limit set by python
sys.setrecursionlimit(100000)
def walk_calls(ent, complexity, seen_funcs):
# grab ent id, add it to list of seen functions
seen_funcs.append(ent.id())
# find all calls from this ent
calls = ent.refs("call", "function", True)
for call in calls:
# check if the called function has been seen; if so, skip to next iteration of loop
if call.ent().id() in seen_funcs:
continue
else:
metric = call.ent().metric(("Cyclomatic",))
# if it has cyclomatic metric, get the product and call walk_calls on it's called 'children'
if metric["Cyclomatic"] is not None:
#print("multiplying complexities!")
complexity *= metric["Cyclomatic"]
try:
walk_calls(call.ent(), complexity, seen_funcs)
except:
print('Recursion error')
return complexityHere in this function we’re starting with the given ent, adding its unique ID to the list of seen entities, then finding all functions called by this ent and iterating through those functions. If any of those functions has already been seen, we skip to the next one, but if not we grab its cyclomatic complexity and multiply it by our running complexity value. Our ‘walk_calls’ function then tries to recursively call itself with this child function as an argument, and if there are any issues an error message will be printed instead. At the end of the recursive walk down the call tree, the final complexity will be spat back out to our main function, which we can then print out to the console.
Alright now to get to the main function of the script:
if __name__ == '__main__':
# Open database
args = sys.argv
db = understand.open(args[1])
# lookup the user-given function, make it lowercase
chosen_ent_raw = str(args[2])
chosen_ent = chosen_ent_raw.lower()
print ("Chosen entity: \'", chosen_ent, "\'")
if not chosen_ent or chosen_ent == '':
# tell user to provide a function name
print("Please provide a function name as an argument to the check.")
elif chosen_ent and chosen_ent != '':
# cycle through all defined functions
for func in db.ents("function ~unknown ~unresolved"):
name = func.name().lower()
# if the function name matches the chosen ent, gather complexity and report it
if chosen_ent == name:
# initialize seen functions tracker and total multiplied complexity
seen_funcs = []
starting_complexity = 0
metric = func.metric(("Cyclomatic",))
if metric["Cyclomatic"] is not None:
starting_complexity = metric["Cyclomatic"]
# walk call tree for this function
final_complexity = walk_calls(func, starting_complexity, seen_funcs)
print ("Function: ",func.name(),"\t File: ",func.parent(),"\t Initial Cyclomatic Complexity of Function: ",starting_complexity,"\t Final Cyclomatic Complexity of Call Tree: ",final_complexity,sep="")In this main function, we’re looking up the entity input by the user, then looking for that entity in each file. If we find a match, we initialize an array of function ID’s that we’ve seen so we don’t end up recursing into an endless circle, start with the cyclomatic complexity metric of the given entity, and call our recursive function ‘walk_calls’ on it.
Great, now that we’ve written this short script we just have to call it from the command line.
The way we’ve written it to read the command, we need to pass the .und database we’d like to run it on as the second argument, and the function we are interested in as the third argument. In my case, I want to run the script on all functions named “main” in one of Understand’s sample C projects. So, to run our script we first need to navigate to the directory where our upython executable is:
Windows:
$ cd “c:\program files\scitools\bin\pc-win64”
Mac:
$ cd “/Applications/Understand.app/Contents/MacOS/upython”
From here, we can run the check with the following arguments:
$ ./upython “/path/to/script.upy” “/path/to/myproject.und” “function_name” [optional: > output_file.csv]
Running this script on the Fastgrep sample project provided with Understand yields the following output:

Here I can see a nicely summarized report of all unique ‘main’ functions in the project, listed alongside the file they were defined in, their initial cyclomatic complexities (just that function, not including nested ones), and the final cyclomatic complexity calculated from walking the call tree.
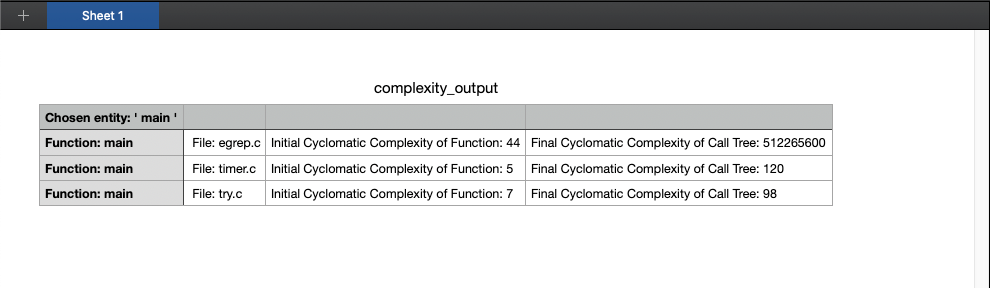
From these results it looks like the ‘main’ functions in ‘timer.c’ and ‘try.c’ are approximately 10-25x more complicated (in terms of decision paths) than we would have initially seen from pulling up the Cyclomatic Complexity metric on those functions. Meanwhile, the ‘main’ function in ‘egrep.c’ has a true complexity of over 512 million. This makes the function over 11 million times more complex than the initial Cyclomatic Complexity indicated it was. This could be the sign of a really large problem with how the function is written – higher complexity code is usually more difficult to test, and more likely to result in errors.
As you can see, using a custom script like this we are able to isolate the most complex and problematic functions, begin to refactor them, and ultimately work toward a more maintainable and modular project.
Happy coding!





