

Do not be afraid of complexity.
Be afraid of people who promise an easy shortcut to simplicity.
― Elif Shafak
The source code for Git (the popular configuration management system) has 363, 691 lines of code, 228, 215 executable statements, 9, 416 functions, and 765,356 connections between all its parts.
– Me, just now
TL;DR: Hyper-Xref technology, and the GUI and API/DevOps tools in Understand, our code maintenance-oriented IDE and platform, make you a safer, smarter engineer less likely to add bugs as you change code.
This article covers:
- Why detailed examination of code change side-effects helps you STOP adding new bugs as you add features or fix old bugs.
- What Hyper-XREF tech is and how it differs from what coding IDEs normally provide.
- How Understand, as a maintenance-oriented IDE/Platform, treats detailed cross-referencing as its core purpose, and shows the tools/features/modes it provides to help you with understanding and examining side-effects from changes you are considering or actively doing to your code.
Already have an IDE? That’s cool. We use more than one here too. See here about why you might want to consider adding an IDE specialized for code maintenance.
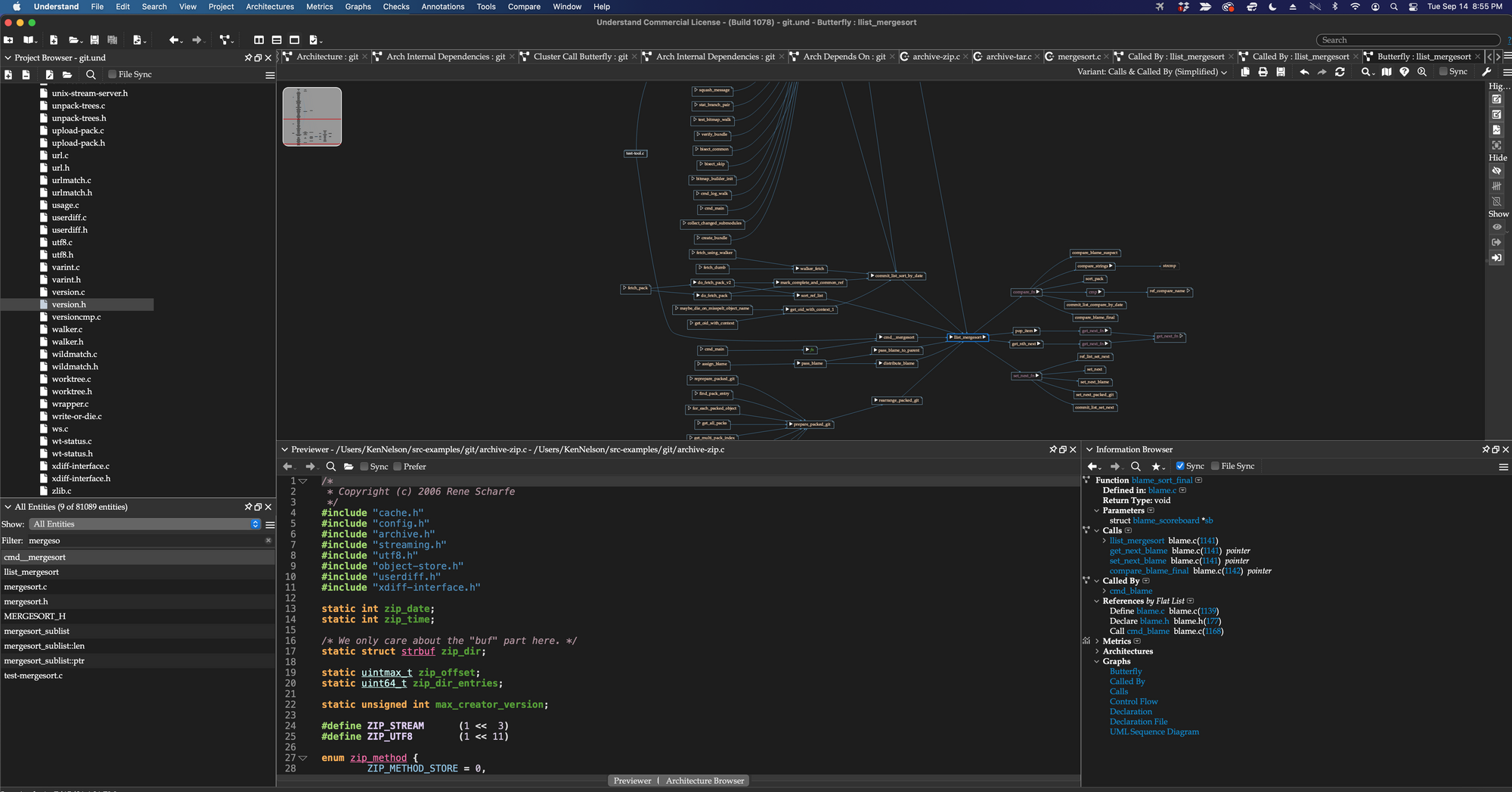
Too Many Parts, Changing Too Fast, Connected Too Densely
Source code is built from named parts (functions, classes, variables, so forth) that depend on each other. The partitioning simplifies and eases software development complexity while the intricacies of their inter-dependencies contribute to errors and bugs.
In non-trivial source code, the number and complexity of these interconnections grow so large, so fast, that no human can know them. They also change, sometimes dramatically, with just small changes to the source code. They change as you change your code, or even just from build settings, compiler upgrades, and language evolutions.
So while we call our product Understand, and it has plenty of features that are used to help software engineers understand the code they work on, its primary benefit to you, as a professional software engineer working on software where bugs can kill people, cost billions, or have missions fail – is so that you DON’T HAVE TO UNDERSTAND, or know, or remember, the inter-connections between the parts of your source code.
You couldn’t know all of them anyway. Not with the resolution Understand does. And you certainly wouldn’t, considering the stakes for the software you write.
But that’s cool… we will tell you, and take you to, all of them.
Why call it “Hyper”?
We don’t internally. We just call them “references”. We use “hyper”, publicly, to separate what we do from normal indexing of source code components. It’s hyper because:
- Everything is referenced.Everything! Every named part of your code, even Goto labels, is hyper-cross referenced.
- Bi-Directional ReferencingAll references are two ways to cover “depended on by” and “depends on”. For example, function foo() calls function foo2() and function foo2() is called-by function foo(). One direction tells you where to look for the side effects you are causing. The other tells you where to look for side-effects you are experiencing (i.e. debugging).
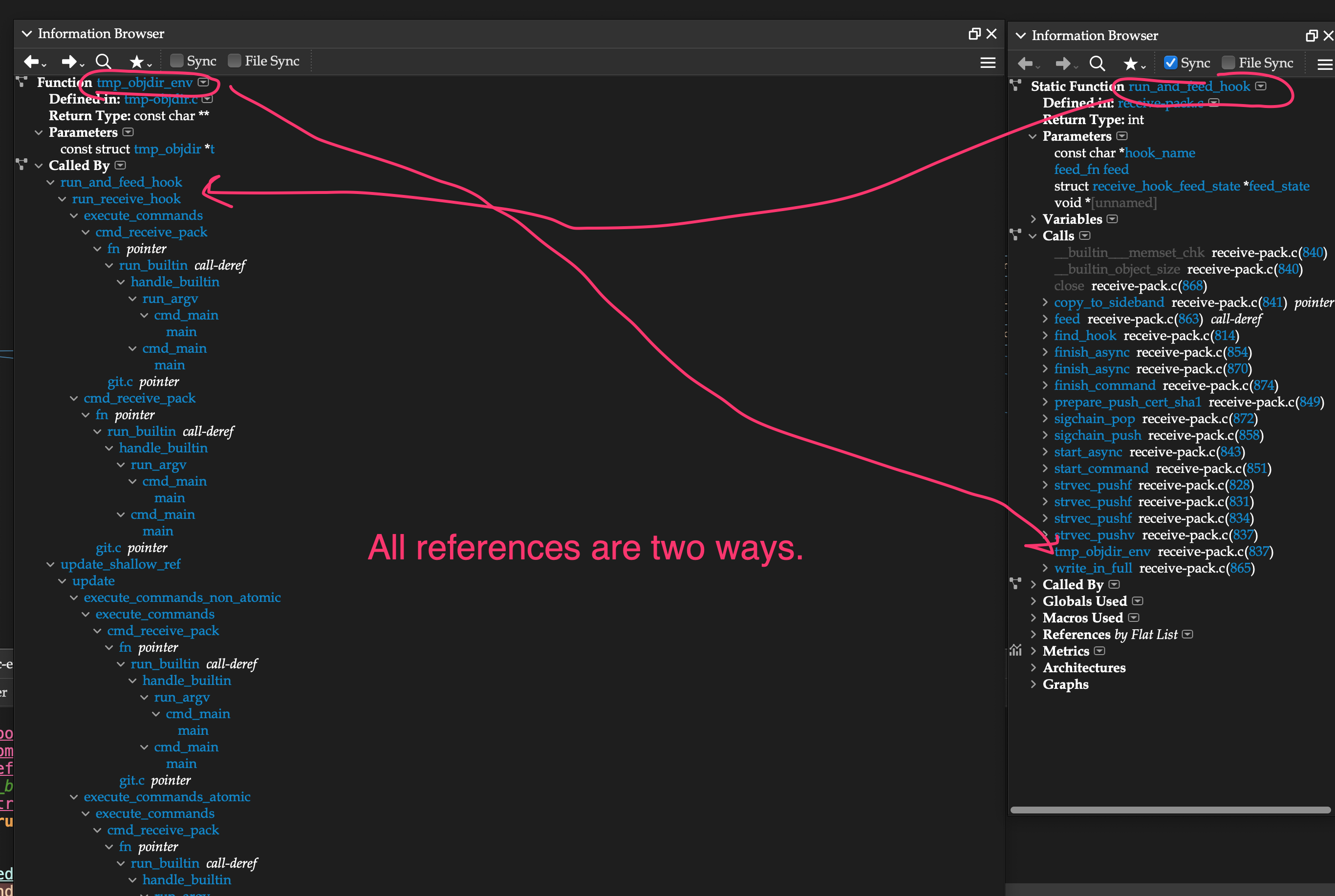
3. References are typed.
We have hundreds of reference types in Understand reflecting all the possible ways code can connect to other parts of code in every language we support. Examples are Calls/CallBys, With/WithBys, Include/Includebys, Override/Overridden-By, with a long list following.
4. Fast.
We optimize and organize our databases/data structures for instant retrieval both in the GUI and in the APIs we provide that give you access to all of this information. Understand is fast and handles HUGE bodies of source code quickly.
5. Filter, View, Organize by Architecture.
We partition references along automatically or manually built architectural divisions that are higher level than what programming languages provide to simplify, structure, and add the ability to filter and sort dependencies.

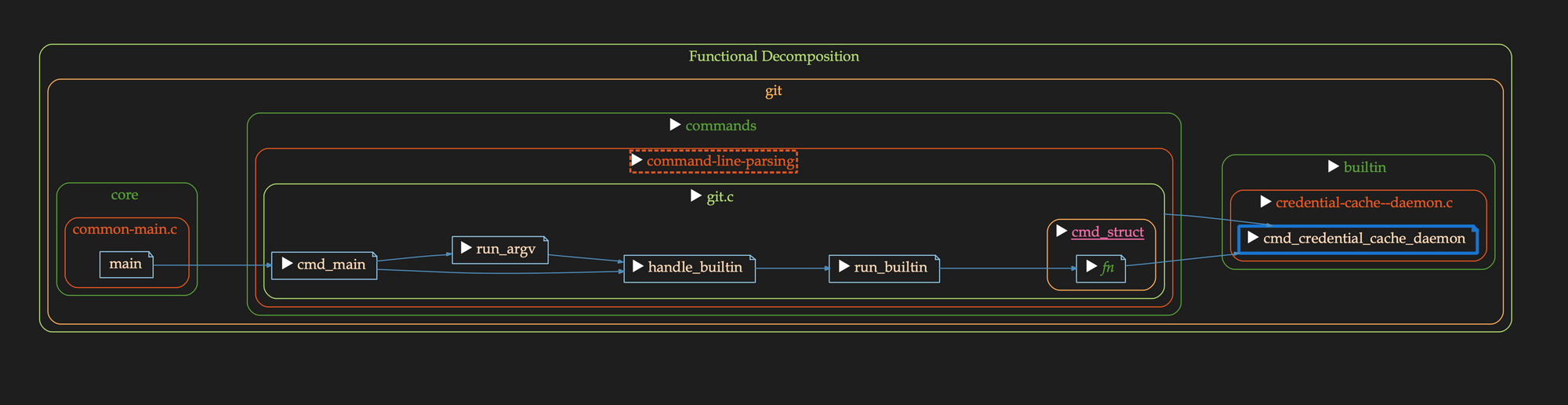
6. Cross-Language Cross-Referencing.
In most cases, our references cross language boundaries (for instance calling FORTRAN from C or C from Java).
Why do I need detailed references?

Code is like a Jenga tower – only one where you can add or remove blocks anywhere – and even build bridges to other Jenga towers. Your job, as a professional Jenga tower builder, is to change the towers without the disappointment of one or all crashing down.
If you know what blocks depend on the blocks you are changing – you may be able to make your changes and still have a standing tower when complete. Or you could decide… this tower is fine as it is, it’s too risky to change it.
The primary uses of detailed relationship tracking are to:
- Show you exactly where to check for proper handling of side effects from changes during software maintenance.
- Help you scope the impacts of possible changes – both in terms of sheer quantity, but also the areas affected and the expertise and people needed to properly implement, vet and test a change.
- Know exactly what code might be causing a side-effect manifesting as a bug in some other part of the code. (i.e. debugging).
Put simply:
- If you change something, go check what depends on it.
- If something is broken, look at what it depends on.
- When considering a change you need to know what you are getting into
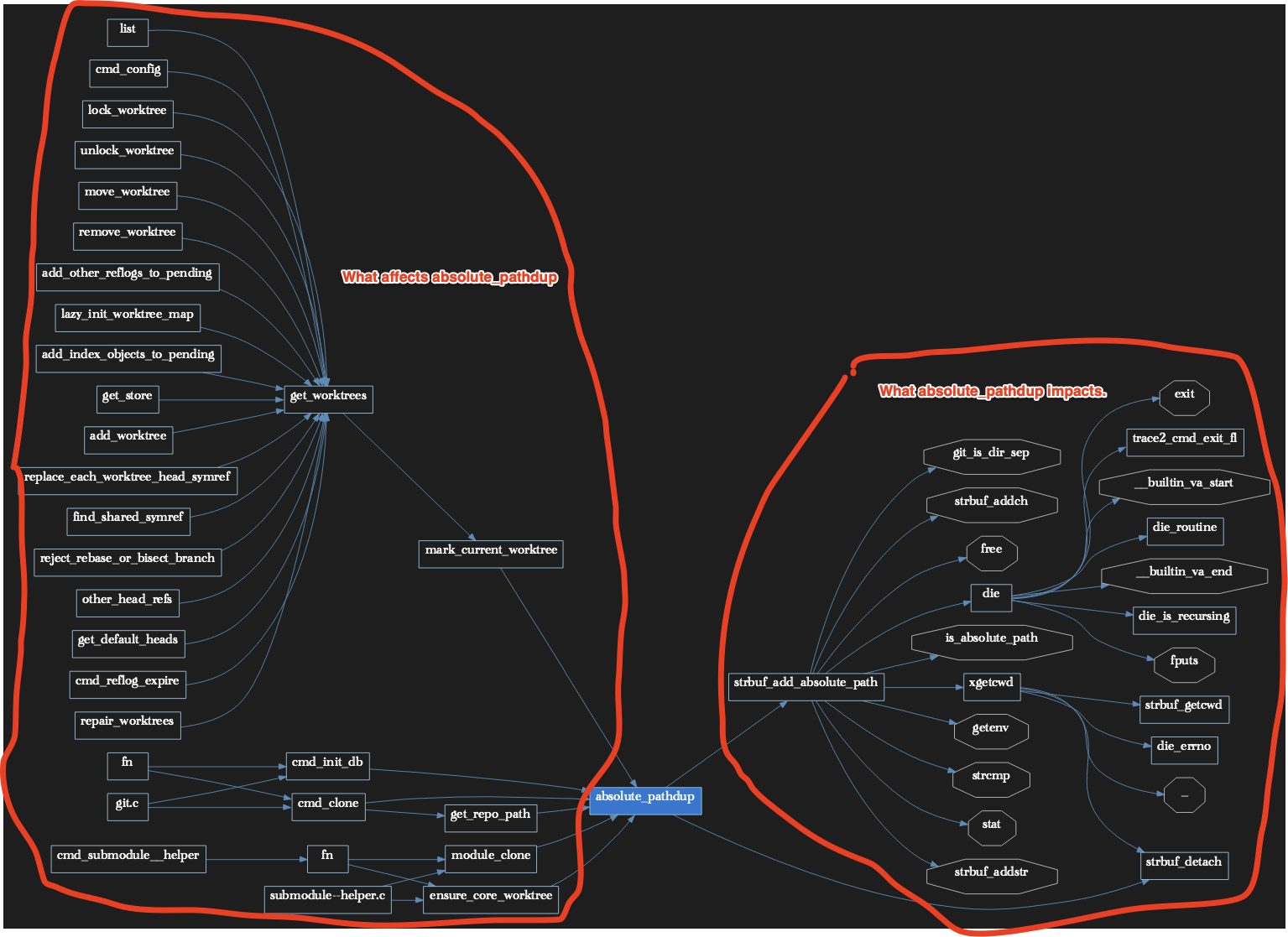
Other editors have Cross References, aren’t they any good?
They are fine. Just not bi-directional, fast, and detailed enough. They may also be inaccurate if not based on a true correct parsing of the source code.
Also, when it comes time to explore massive numbers of cross-references, diving down dozens of levels in your source code parts relationship hierarchies, you need special tools built for doing that task. Different types of impact assessments require different ways of browsing them. Understand’s basic mode of operation is to browse connections in code – even as you edit. It also has dozens of tools, each of which is very configurable, for walking references.
It’s not a given that the side-effect that will crash the plane is just one level from the change – it’s more likely to be 23 levels, thru 15 other interconnections. You’ve got to check them, and you need to not just know them but stay organized and efficient as you check them.
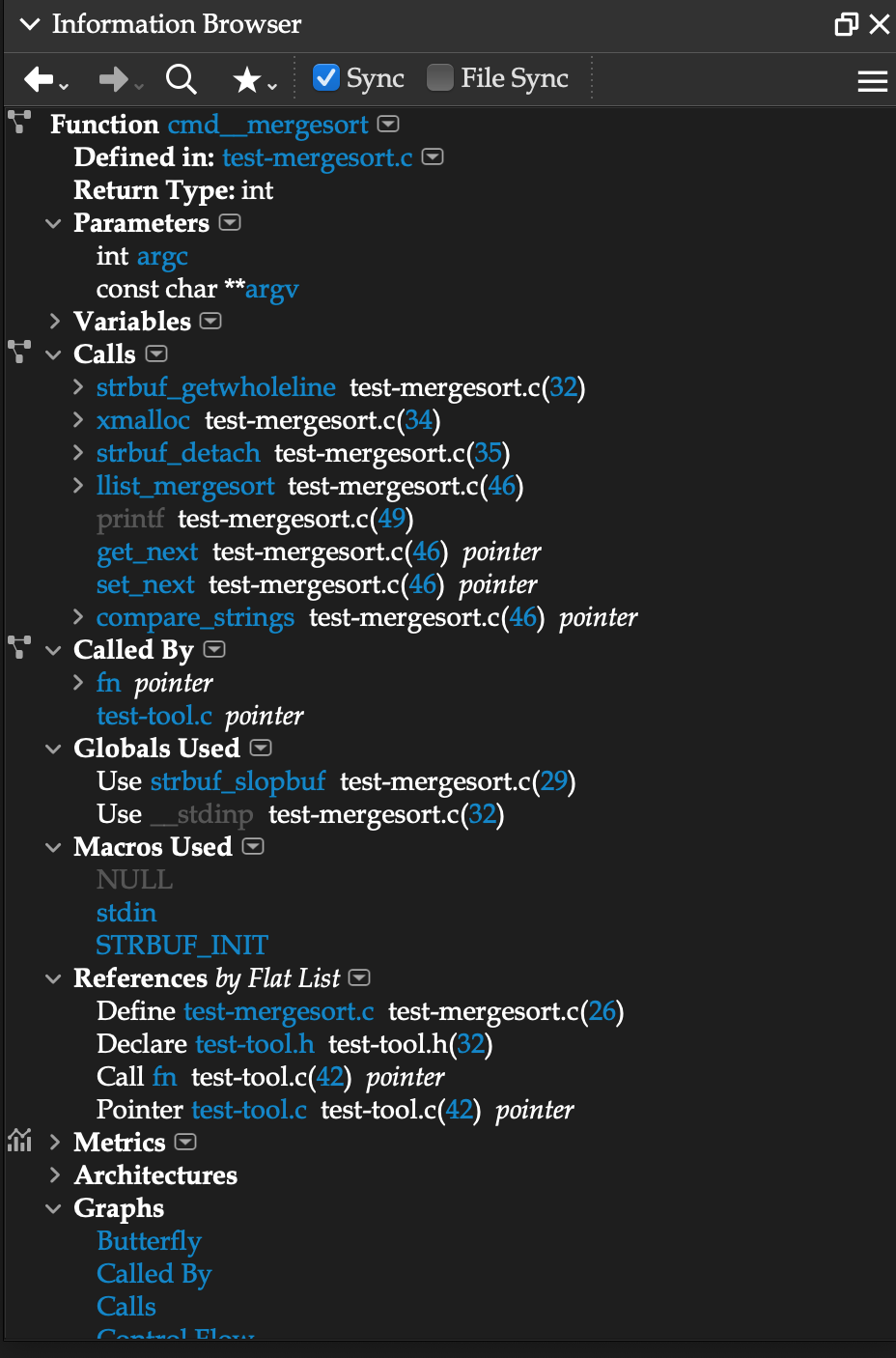
Following Connections with Understand
Understand looks like, and shares many features with, a traditional IDE. Its primary role, though, is to help you follow and understand connections between parts of your software.
Cross-referencing/code connections are like air to Understand – everywhere and easily accessed.
It has 6 classes of tools for browsing the hyper-references it builds for your source code:
- Powerful traditional programming IDE with Maintenance oriented Hyper-Cross references available in one click (or less).A colorizing, code-savvy source editor with the skills of common coding IDEs, that is also very aware of the connections between code and provides you with one click, “web” like browsing of those connections. All visits in Understand are remembered in history so that you can walk down (0r up) a side-effect chain. The editor is re-used in other tools – like its differencing tool, the code standard compliance tool “CodeCheck”. The general rule in Understand is that if you see code, you can also see what its relationships are in one click.
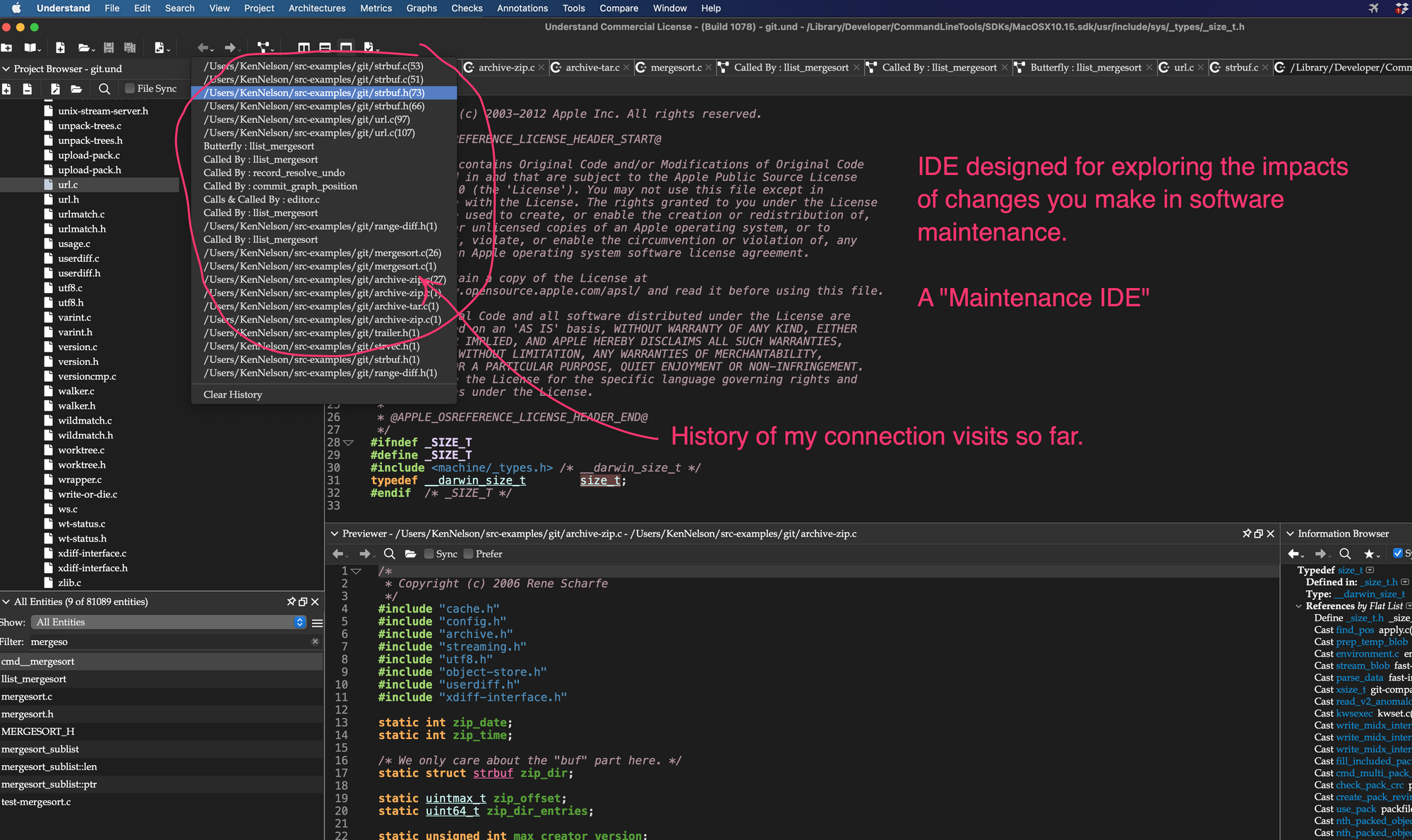
30 (oops 45) seconds to browsing references in Understand. Simple. Quick. Everywhere!
2. Browsers and Lists of the Parts of Your Code
Every named part of your code can be found – quickly and precisely using tools like the Project Browser, Entity Filter, and Entity Locator.
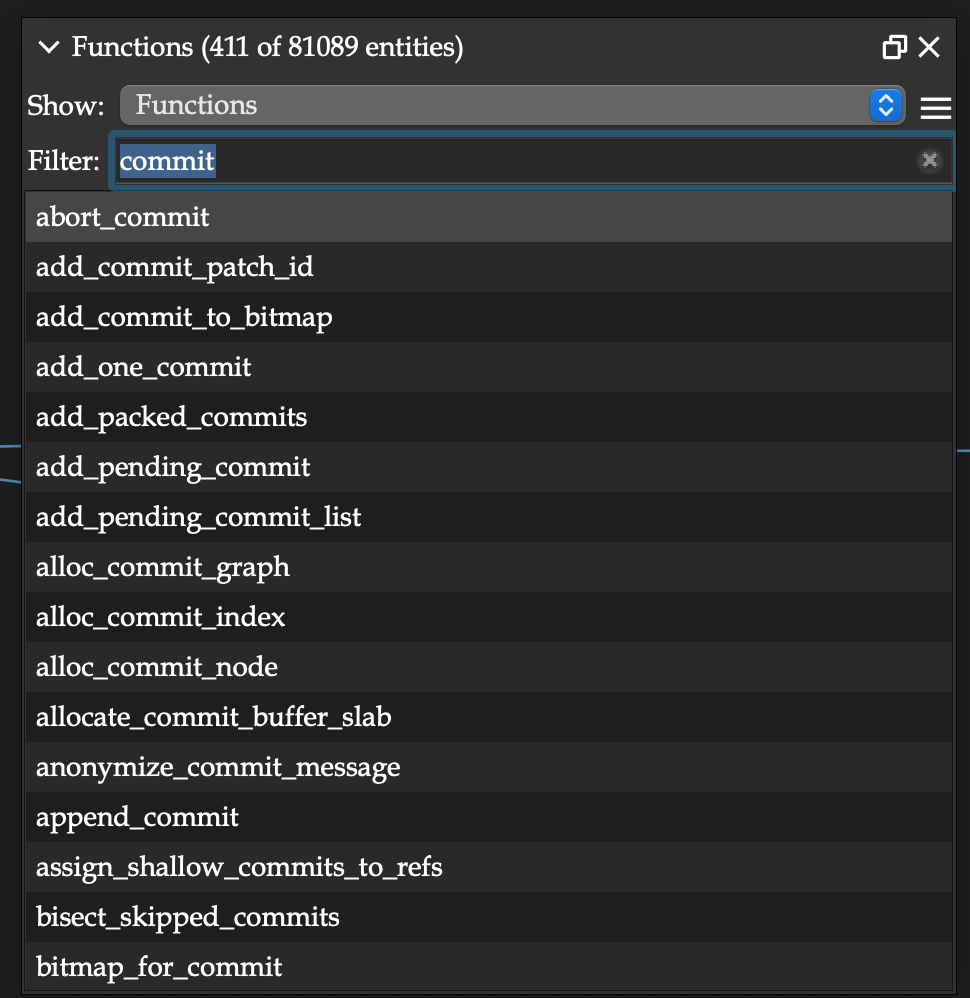
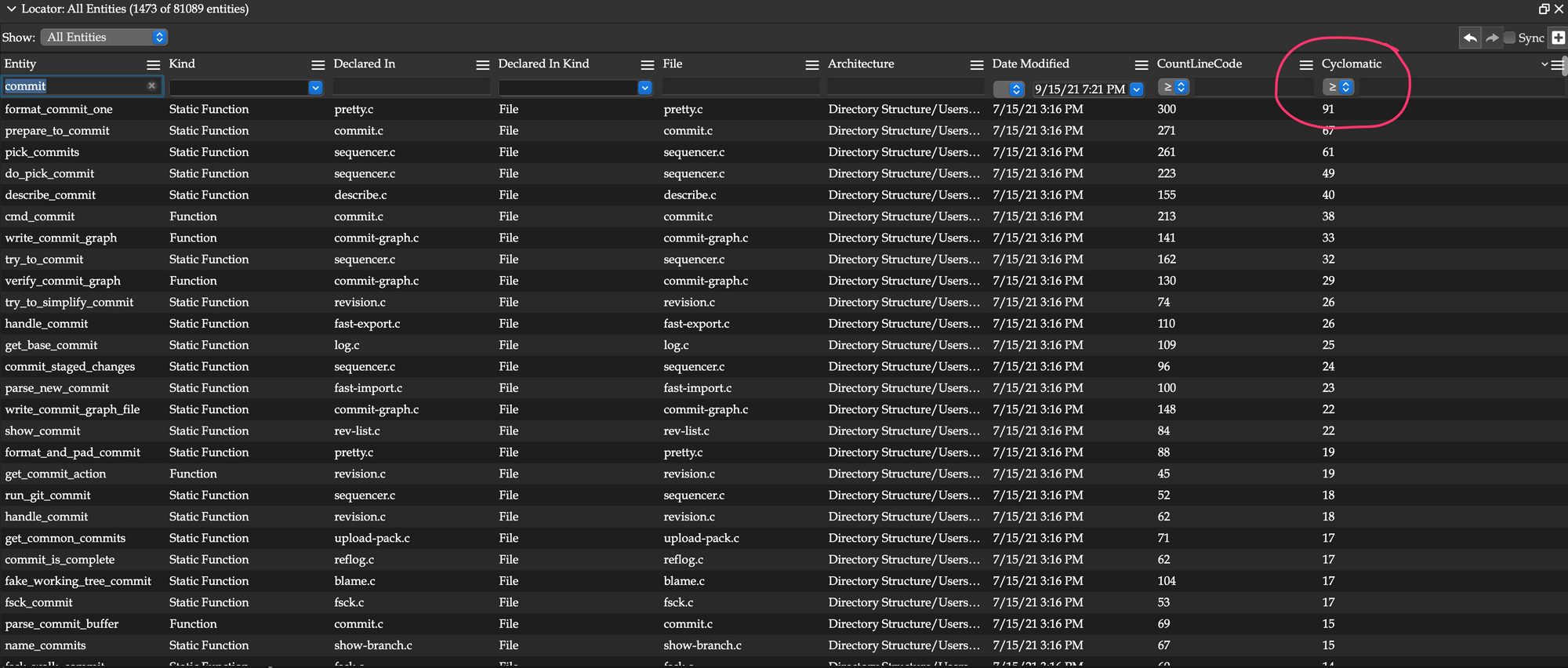
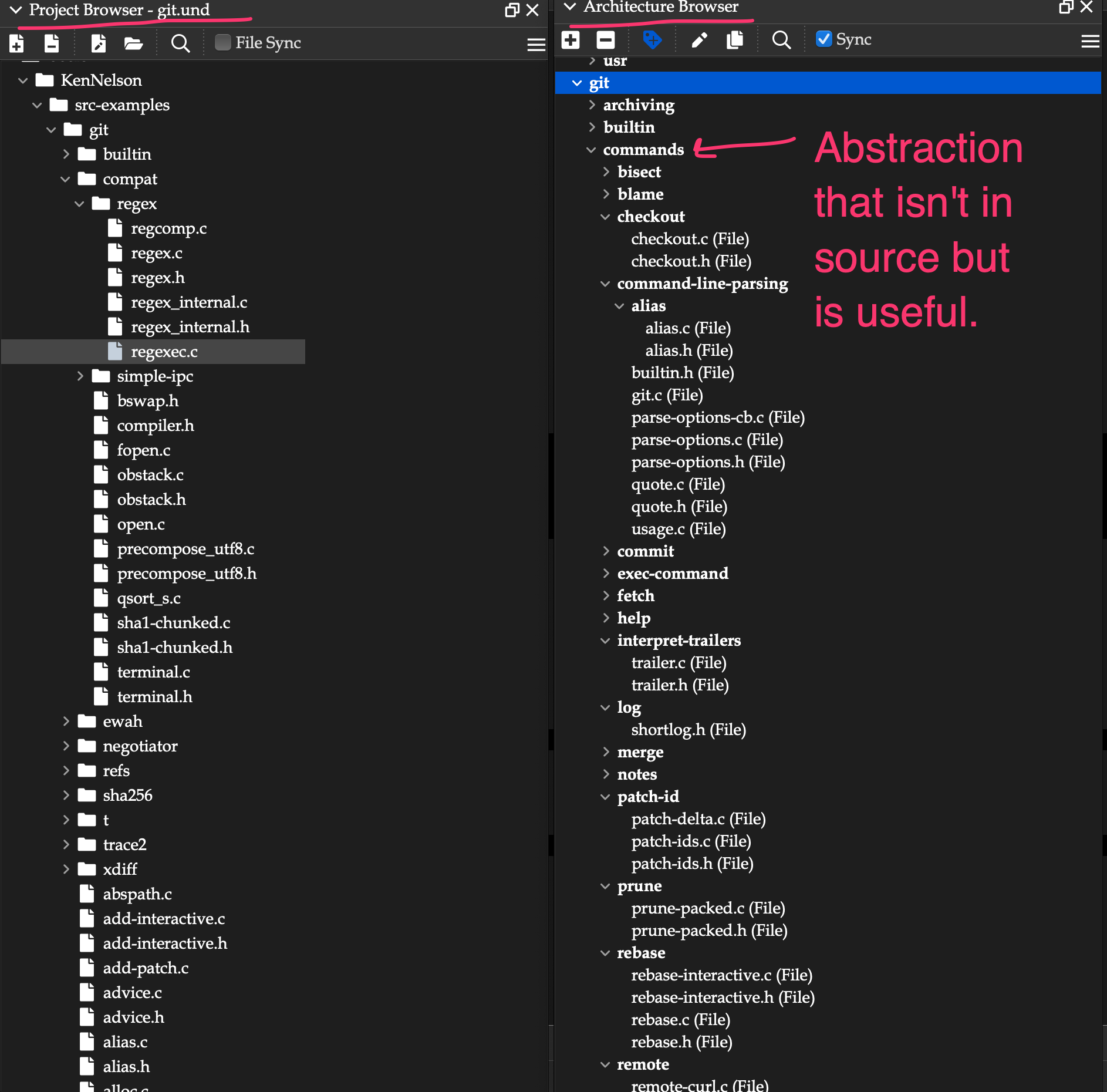
3. Reference Browsers/Traversal Tools
Git’s source code has over 700,000 connections between the code in it. At some point, the main problem is sorting through what connections matter, and even after filtering or sorting, being able to look at them efficiently.
Understand has several views for this. The primary one being the “Information Browser”, which is a core tool in Understand. Or “tools” – because you can have any number of them up at once.
The Information Browser shows all the connections to and from a given source code part – which we call “entities”. https://www.youtube.com/embed/l4ny8CTa36k?feature=oembed
Another example of a dedicated optimized reference traversal tool in Understand is the “Explorer”. It works like a Mac Navigator view, only letting you explore – in a fixed size window space hierarchies of any complexity and depth.
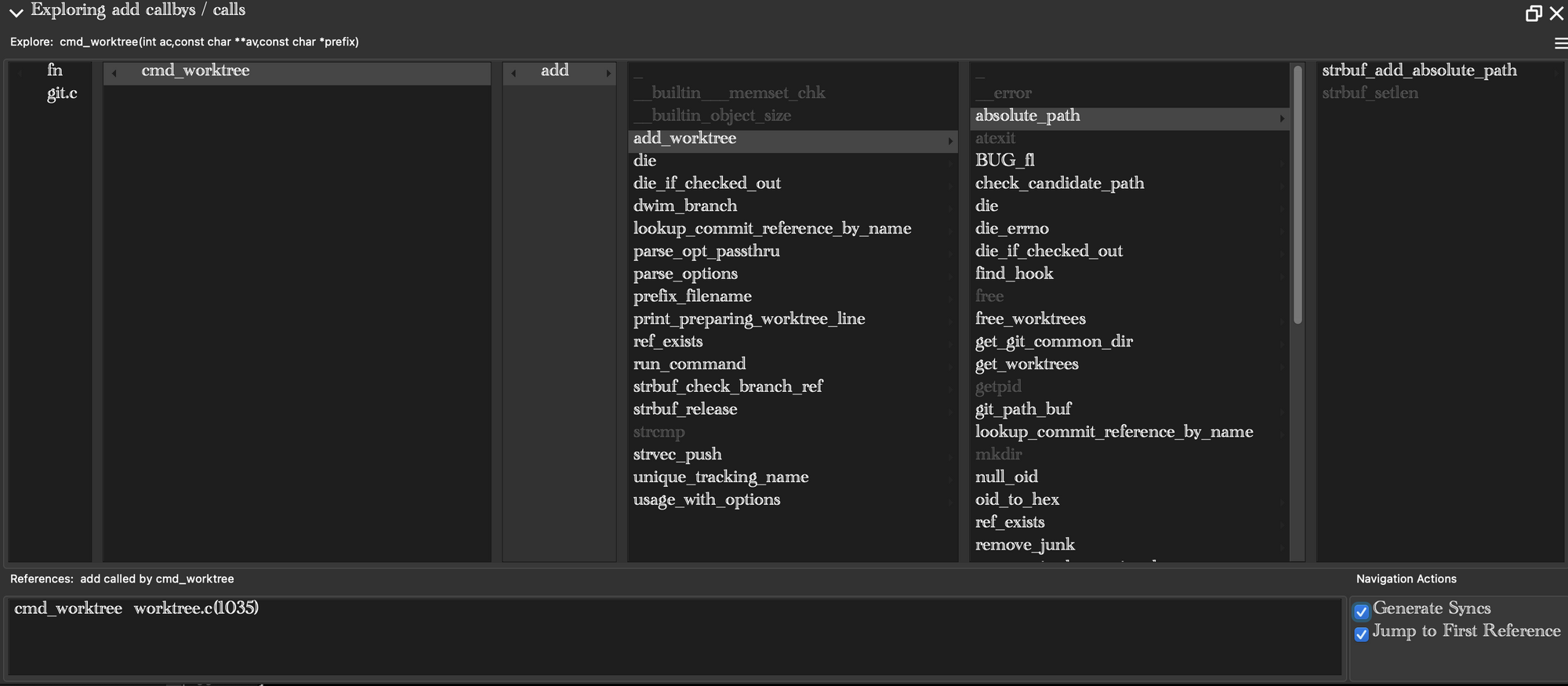
https://www.youtube.com/embed/RkSkt8kBb1Q?feature=oembed A quick exploration of the “Explore” tool with me. That’s an awkward thumbnail. Dang it.
4. Graphical Diagrams of Reference Relationships
A picture is worth 10,000 lines of code! Understand graphs code a zillion different ways, with different purposes for each graph. We even wrote an article just about our code graphing tools:
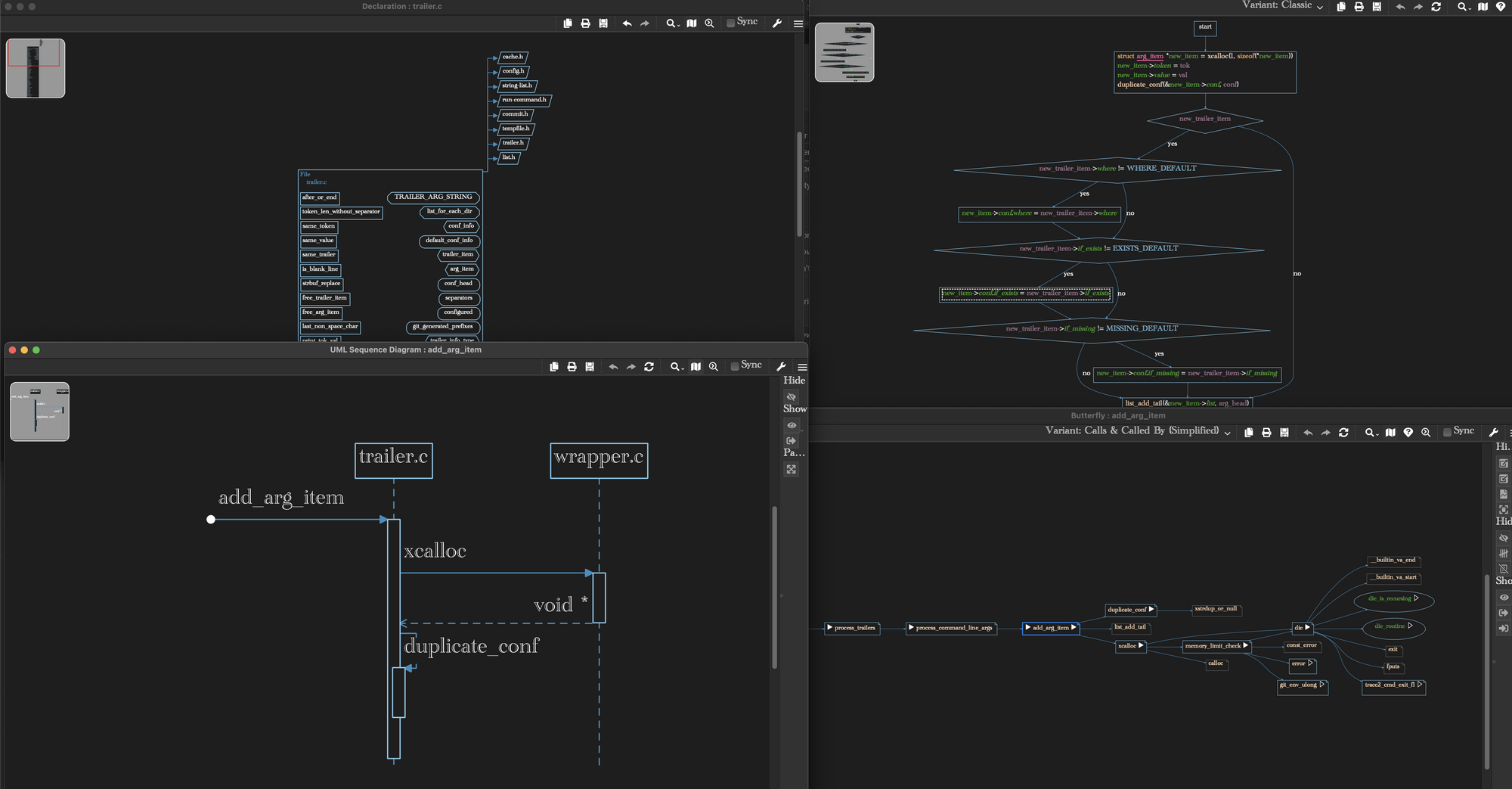
5. Dependency Checking Tools with Rule Editor and Violation Investigation
Dependency problems are the heart of the problem of maintaining code. When you make a change you cause ripples in the code. You are in “dependency hell” when the ripples break your programs, or cause bugs you didn’t intend. The first rule of dependency hell is to stop digging. Understand’s Dependency tool helps you stop digging and start improving the code. You do this by setting rules of what ripples can go where. For instance:
“Kernel” can never depend on “GUI”
Why would you want your kernel to ever depend on your GUI? It seems odd, but it happens.
Using Understands Dependency Rule builder you can specify rules like “Crypto cannot depend on Git Commands or Git Support Library” and enforce them automatically.
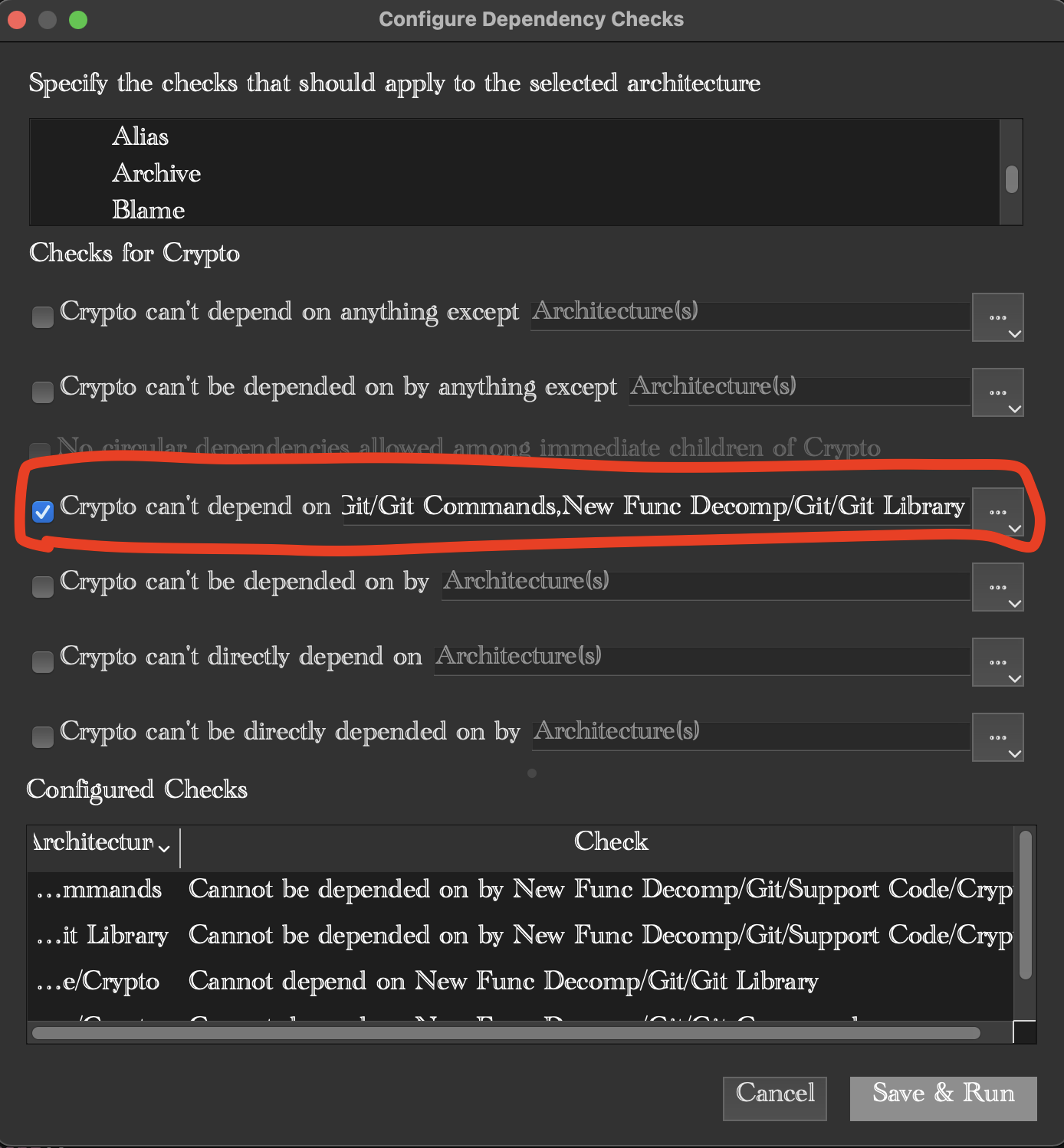
What you are doing is defining in advance the dependencies you are willing to accept – and then enforce them automatically – keeping you out of Dependency Hell, or at least minimizing how further you dig a hole by making violations at least be considered before being done.
6. Python & PERL APIs so you can write programs that check, report, investigate and document your source code
Every project is different. You might have rules, for instance, that forbid the use of any code that has an open-source license in it.
Or you might want to use Open Source but keep track of it so you can make sure you are in compliance with their licensing agreements.
That’s where the API comes in. With it, you can write scripts – (you are a programmer right??) that use Hyper-XREF data as you see fit.
For instance, a script to check for Open Source licenses, and to then report all other code that is dependent on it, or to prove that no important code is dependent on it.
Whatever you want. You have full access to all the data.
To learn more, visit this documentation.
Summary
Understand’s Hyper-XREF technology is a detailed cross-referencing of all the interconnections in your code. Understand’s maintenance-oriented IDE uses these references to help you be smarter as you change your code and to automatically reduce unnecessary or risky interdependencies.
Thanks for reading. I’d welcome your thoughts, suggestions, and feedback.
Ken Nelson
Co-Founder and President
SciTools





