

TLDR:
Making a functional decomposition architecture of the source for GIT helps me understand code that is new to me much better while also making an upcoming deeper analysis more organized, clear, and concise.
Details:
I’ve got a little side project examining the source code for open source projects that are influential in the world. For instance, the Imperial College COVID pandemic simulation source code.
Today’s efforts examine GIT – the source code revision control system that all my projects, and most of the software development world, use.
 git
git
My overall goals are to:
- get a general sense of the quality of GIT code, including any serious defects
- identify what external source code GIT depends on
- build a functional decomposition architecture to help me make more sense of GIT
This article will focus on goal 3 – making a functional decomposition architecture – that will be a foundation I can use to then go about examining GIT for the first two tasks.
Quick Examination of GIT source code
Here is the initial graph I got of “dependencies” in GIT – sort of “not helpful”. This is largely due to the lack of division of the source code into functional directories. It’s mostly a bunch of C and H files in one directory.

In general, very connected, and quite a few mutual dependencies:

First impressions… “git” runs the world of software development but looks like it’s a fragile mess. And I say that with love. I often feel this way when I examine important software. It got important by being good, being used, and being maintained and this can be what a decade+ of even well-managed maintenance looks like.
Let’s see if we can learn about GIT and perhaps abstract how it is built to more human comprehendible forms.
Adding Structure without Changing A Thing
My first task is to read through the code and try to “name” things. To do this I simply load up the project and visit files, reading and thinking.
I did that for a while, maybe 1/2 an hour and I start to make some sense of the general structure. For instance, there is a “server“, and there are “commands“, and they need to be “parsed“. There are also core things, like diffing, and so forth.
The “names” of things are starting to form in my head. I start to add these names to a Functional Decomposition Architecture – and place source files in them.
Note that placing a file into an architecture is “virtual” and doesn’t change physical locations or any code relationships.
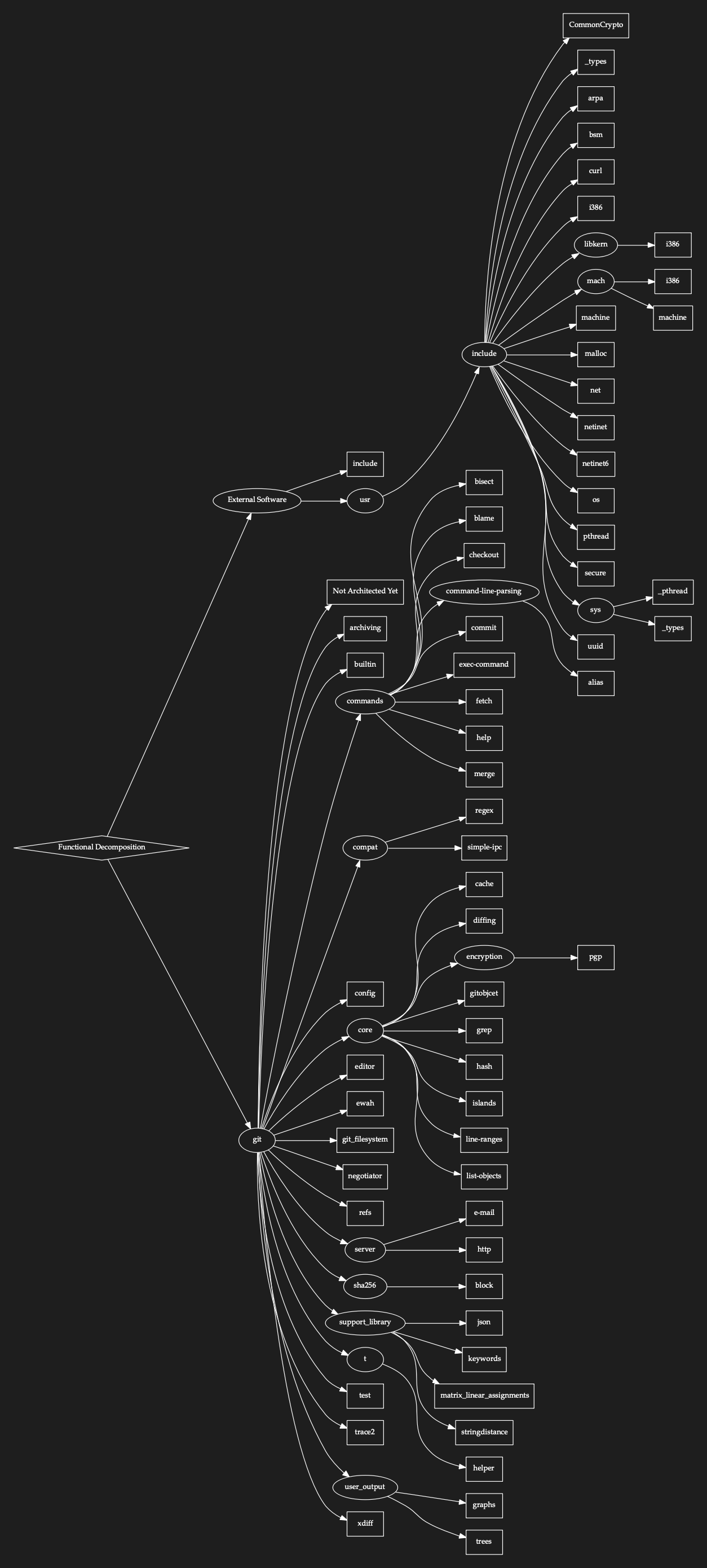
If I were a contributor to GIT this language and the way of describing the parts of GIT would already be established – as I’m sure it is for any projects you are involved with. I’m making it myself, and it will probably differ greatly from what those internal to the project use.
A partially developed functional decomposition architecture can still be beneficial,
Look above and check out that call tree for “main()” again… big, deep, complicated.
Here is a newer view of the main(), using a cluster call graph organized by a functional decomposition architecture I’m about halfway through building:
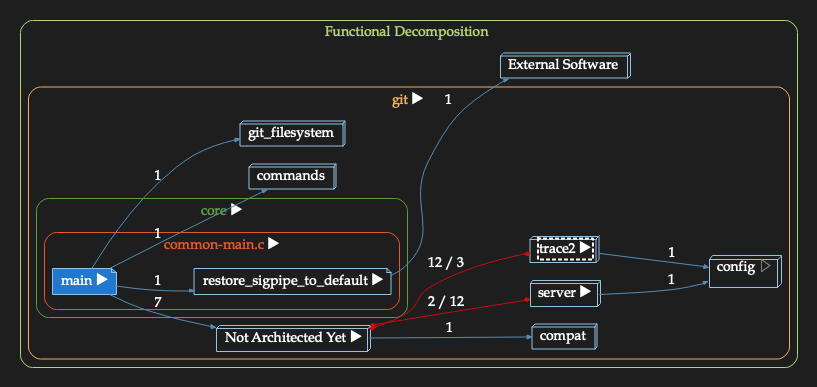
Even though the Functional Decomposition is only about 1/2 done, the graph of how main() works is becoming simpler, clearer, and more informative.
FYI… box “Not Architected Yet” – that is where source code I haven’t organized yet is placed as a place holder.
If I want to explore more details, I can click on the nodes and see the details in just that section. For instance, here I examine main() going into server – and then into the http portion of server:
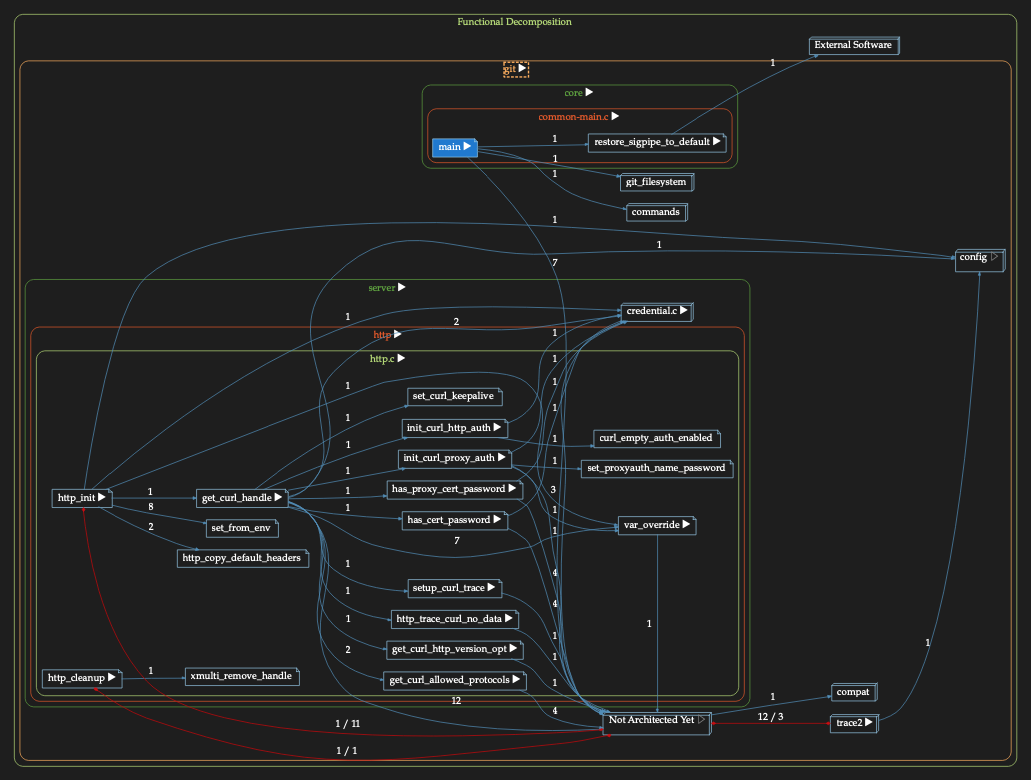
The graph gets bigger with the advantage of the details being about what I asked for, not all connections.
The Functional Decomposition architecture I’m building helps reduce graph complexity while lifting comprehension.
Final Architecture
A couple of hours later (give or take), I’ve looked at every source file and have created a tentative first crack at a final functional decomposition architecture. I’m sure it has lots of mistakes in it, but that doesn’t really matter too much for this excercise. It is going to help me understand this code, and organize further work on it much more readily.
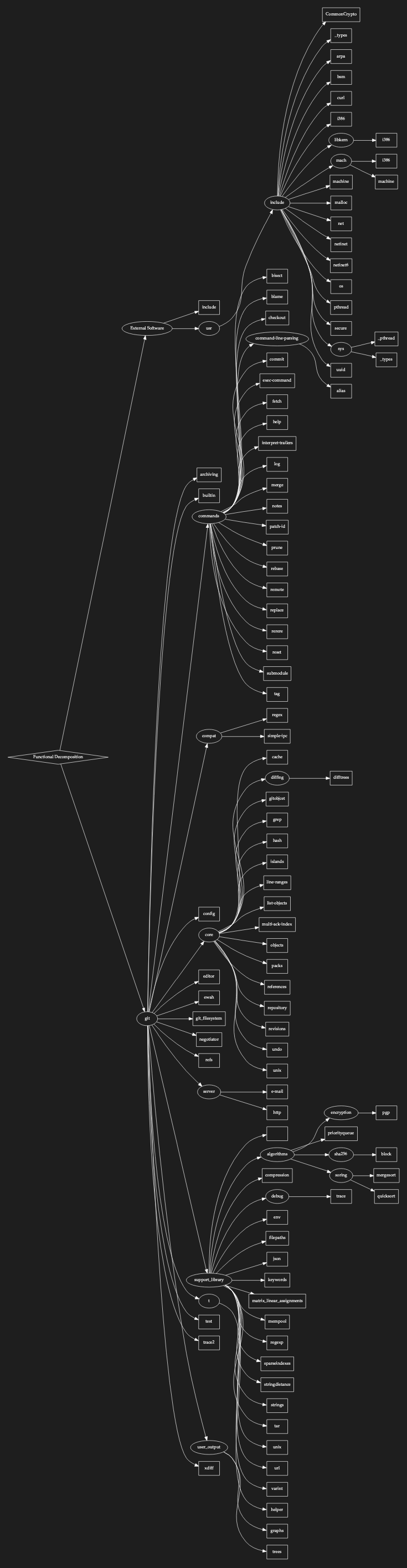
Here it is (shown as a hierarchical tree):
Taking a peek at that “main()” function, we have a clearer picture of how it is built:
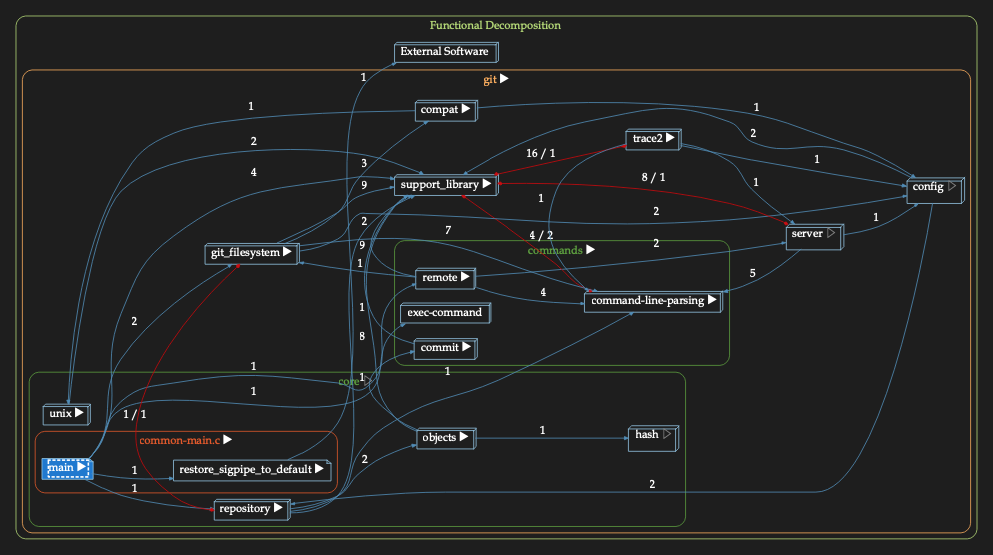
Now look at the dependencies between architectural components (1st level):

That is complicated, but a LOT more readable and useful than where we started:

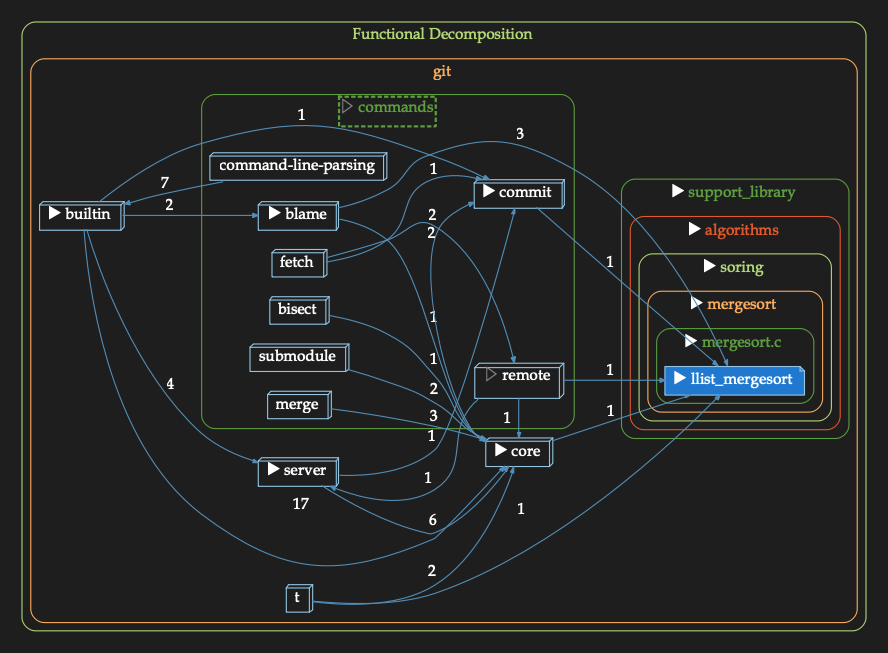
Another benefit… clear graphs on the impact of possible changes. For instance, if I want to change the merge sort code that GIT uses, this is an overview of how what might be affected:
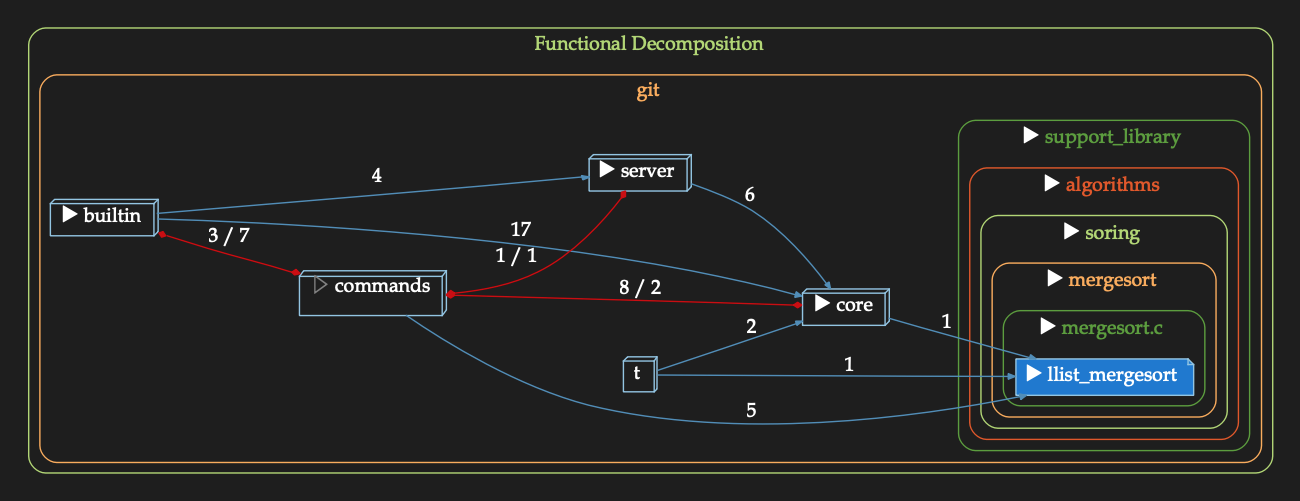
which is simpler than this:

The first is useful for understanding what needs to be done. The second, for the details of where you need to go to assess impacts.
If I ask the question “what git commands depend on merge sort”… here’s the answer (found by expanding the node for “commands”).
Conclusion:
I’ve spent about 4 hours going thru GITs code building up my best first crack at a functional decomposition architecture.
It is wrong, probably in many ways.
However, I understand GITs code much better than I did, and I have a way to keep improving my understanding of it going forward – and importantly, a way I can share with others who want to look at GIT with me.
Happy gitting!
Questions, comments, suggestions? Shoot me an e-mail. [email protected]





