

Abstract: Identifying which CodeCheck scripts are taking a long time and three functions that might be slowing down your custom API scripts.
Have you ever started a CodeCheck run and wondered what on earth is taking so long? I have. How do you find the problematic scripts?
Identifying the Culprit
The question of “what check is taking the longest” is so common, that there’s actually a built-in command for it. From the command line, you can add the switch “-showchecktimes” to get a report of the time spent on each check:
und codecheck -showchecktimes "SciTools' Recommended Checks" outdir/ project.und
Then, at the end of the log, you’ll see a report like this one:
Check run times: 1 RECOMMENDED_03 01:09.877 2 RECOMMENDED_12 24.133 3 RECOMMENDED_00 17.743 4 RECOMMENDED_05 16.359 5 RECOMMENDED_08 12.784 6 RECOMMENDED_16 12.448 7 RECOMMENDED_17 05.152 8 RECOMMENDED_07 04.697 9 RECOMMENDED_09 02.271 10 RECOMMENDED_06 01.814 11 RECOMMENDED_14 00.624 12 RECOMMENDED_13 00.571 13 RECOMMENDED_11 00.555 14 RECOMMENDED_04 00.506 15 RECOMMENDED_10 00.256 16 RECOMMENDED_01 00.147 17 RECOMMENDED_15 00.106 18 RECOMMENDED_02 00.065 CheckTimes Count = 18 Checks Started = 18 Checks Ended = 18 Check Times Lost = 0 Total Check Times: 02:50.108
This result, from one of the GitAhead databases described here, shows that nearly half of the 7 hours spent running CodeCheck in that article was probably due to RECOMMENDED_03, the floating-point equality check.
Profiling
Identifying slow scripts is only the beginning. The next step is finding out which part of the script is causing the bottleneck. The best way is a profiler, if possible. However, without access to the Understand source code, profiling isn’t an option for most scriptwriters. The good news is I have access to profiler results that might be a good start for improving your own scripts. The rest of this article describes three functions that might be the bottleneck in your script.
The ent.refs() function
Dependency analysis completely changed in Fall 2021 in order to better support multiply defined and unresolved entities. While implementing the new version of dependencies, one of the problems was returning to the original speed. The previous version of dependencies could be run in about 25 seconds for the Understand source code Directory Structure architecture. The new version took over a minute. The major difference is the ent.refs() function. Here’s a profile:
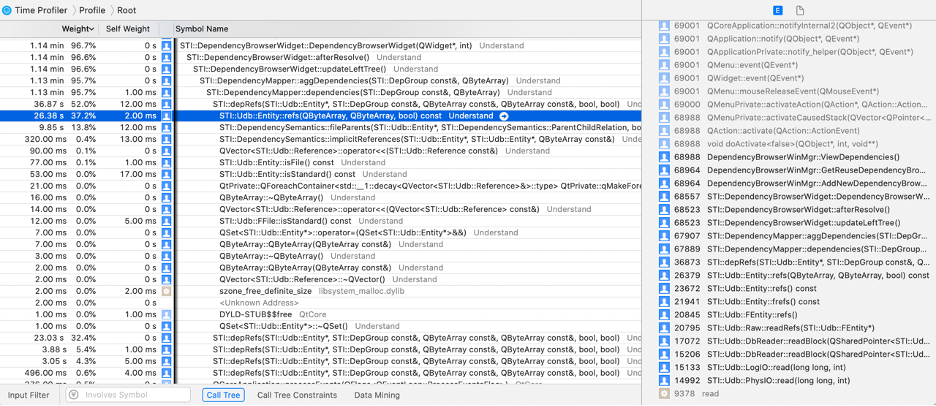
In previous versions of Understand, architectures could only contain file entities. This meant that filerefs() was called once per file, whereas the new implementation called refs() at least once per an entity. To understand why that makes such a big difference, consider this small example:
// File 1
void bar() { foo(); }
// File 2
void foo() { baz(); }
There are three important references for foo():
- foo() is defined in file2
- foo() calls baz() in file2
- foo() is called by bar() in file1
A call to refs() returns all references, so foo.refs() will include all three references. A call to filerefs() will return all the references in a file. So, file2.filerefs() will include the first two references for foo() but not the final reverse reference. The reason that refs() takes a lot longer than filerefs() is because it has to find those reverse references.
For (forward) dependency calculations, only the forward references matter. So, to return the speed to the original, filerefs() is called on the containing file and the references for a particular entity are found from that list, avoiding the call to refs(). As long as an entity is not multiply defined, calling filerefs() on the entity’s file will include all the forward references for that entity.
In fact, forward references with filerefs() is so much faster than refs() that reverse architecture dependencies aren’t directly calculated. Instead, forward dependencies are calculated and then inverted.
The refs() call is the main slow-down in RECOMMENDED_03 (floating point equality) check. For variables, the check finds the underlying type of the variable by following the “typed” reference. You can turn off this type check by unchecking the “Include typedefs” option, which reduces the speed of the check from over a minute to 06.752 seconds.
The db.lookup_uniquename() function
There used to be an interactive report to find which entities have changed between two databases. That was replaced with the changed entities locator:
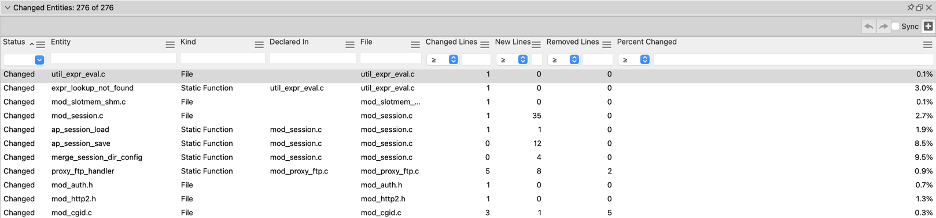
One of the major improvements in Understand 6.2 is the speed of that changed entity calculation. The Apache sample project used to take about 19 seconds (on a MacBook Pro 2019, averaged over 4 runs). Now it takes less than a second. What changed? Here is a profile result from the previous implementation of compare:
Heaviest Stack Trace: 35 61223.0 Understand (59788) :0 34 59309.0 _pthread_start 0x134888 :0 33 59309.0 <Unknown Address> [inlined] 32 libsystem_pthread.dylib 59309.0 thread_start 31 libsystem_pthread.dylib 59309.0 _pthread_start 30 QtCore 59309.0 0x106fbae00 29 Understand 59309.0 STI::Compare::Worker::run() 28 Understand 58240.0 STI::Compare::Worker::processPair(STI::Udb::Entity*, STI::Udb::Entity*, QString) 27 Understand 50488.0 STI::Compare::Worker::lookup(QString, bool) 26 Understand 50477.0 STI::Udb::Db::lookupEntityByUniquename(QByteArray) /Users/natasha/sti/src/understand/udb/Db.cpp:457 25 Understand 50477.0 STI::Udb::Uniquename::lookup(QByteArray, STI::Udb::Db*, bool) /Users/natasha/sti/src/understand/udb/Uniquename.cpp:177 24 Understand 50447.0 STI::Udb::Uniquename::lookup(QByteArray, STI::Udb::Db*, QList<STI::Udb::Entity*>&, bool) /Users/natasha/sti/src/understand/udb/Uniquename.cpp:219 23 Understand 42956.0 STI::Udb::Entity::uniquename() const /Users/natasha/sti/src/understand/udb/Entity.cpp:716 22 Understand 42908.0 STI::Udb::Uniquename::encode(STI::Udb::Entity const*) /Users/natasha/sti/src/understand/udb/Uniquename.cpp:155 21 Understand 21628.0 STI::Udb::Uniquename::encode(STI::Udb::Entity const*) /Users/natasha/sti/src/understand/udb/Uniquename.cpp:163 20 Understand 9455.0 STI::Udb::Entity::projectname() const [inlined] /Users/natasha/sti/src/understand/udb/Entity.h:203 19 Understand 9445.0 STI::Udb::FEntity::projectname() const /Users/natasha/sti/src/understand/udb/FEntity.cpp:107 18 Understand 9435.0 STI::Udb::FFile::portablename(STI::Udb::FEntity const*) const /Users/natasha/sti/src/understand/udb/FFile.cpp:412 17 Understand 9094.0 STI::Project::File::portablename(bool) const /Users/natasha/sti/src/understand/project/File.cpp:135 16 Understand 9089.0 STI::Project::File::portablename(STI::Project::Portability, bool) const /Users/natasha/sti/src/understand/project/File.cpp:167 15 Understand 4836.0 STI::Project::File::tryRelativename(QString, QString) /Users/natasha/sti/src/understand/project/File.cpp:215 14 Understand 1524.0 STI::Project::Path::fromDir(QString, QString, bool) /Users/natasha/sti/src/understand/project/Path.cpp:166 13 Understand 1344.0 STI::Project::Path::Path(QString, QString, bool) [inlined] /Users/natasha/sti/src/understand/project/Path.cpp:27 12 Understand 1343.0 STI::Project::Path::Path(QString, QString, bool) /Users/natasha/sti/src/understand/project/Path.cpp:85 11 QtCore 1134.0 QString::split(QChar, QFlags<Qt::SplitBehaviorFlags>, Qt::CaseSensitivity) const 10 QtCore 1126.0 0x106f1e6c0 9 QtCore 570.0 0x106da8ea0 8 QtCore 478.0 0x106d9e470 7 QtCore 391.0 QArrayData::reallocateUnaligned(QArrayData*, void*, long long, long long, QArrayData::AllocationOption) 6 libsystem_malloc.dylib 369.0 realloc 5 libsystem_malloc.dylib 314.0 malloc_zone_realloc 4 libsystem_malloc.dylib 247.0 nanov2_realloc 3 libsystem_malloc.dylib 105.0 szone_malloc_should_clear 2 libsystem_malloc.dylib 98.0 tiny_malloc_should_clear 1 libsystem_malloc.dylib 36.0 tiny_malloc_from_free_list 0 libsystem_malloc.dylib 10.0 tiny_free_list_add_ptr
Why does looking up entities by unique name take so long? The function does a fuzzy match to improve matching between databases or within the same database over time. But, fuzzy matching comes at a price, and that price is speed.
Instead of calling lookup_uniquename for every entity, the changed locator now finds all the exact matches and then does fuzzy matching for only the unmatched entities. This reduced the time for Apache from about 19 seconds to 2 seconds.
The ent.contents() function
The current implementation takes about 1 second for Apache. Where did the last speed boost come from? To calculate the changed lines, the equivalent of ent.contents() was called on every pair of changed entities. However, each call to ent.contents() opens the file (and may also involves a call to ent.refs()). Internally, the code was modified to only call contents() once per file and index into that string to find the entity’s contents.
It’s worth noting that scriptwriters should still prefer using contents() or the lexer over opening the file directly using Python or Perl. That’s because git comparison projects may be using a version of the file that’s different than the version on disk.
By the way, the speed improvement of reducing calls to contents() for git comparison projects is even bigger. For GitAhead compared to a previous git comparison version, the time went from around 8 seconds to around 2 seconds. That’s 25% of the original time, instead of the 50% for Apache.





