

TLDR:
Adding a bit of human knowledge to the automatically built Directory Structure architecture can improve its visual appeal and utility quite a bit.
Details:
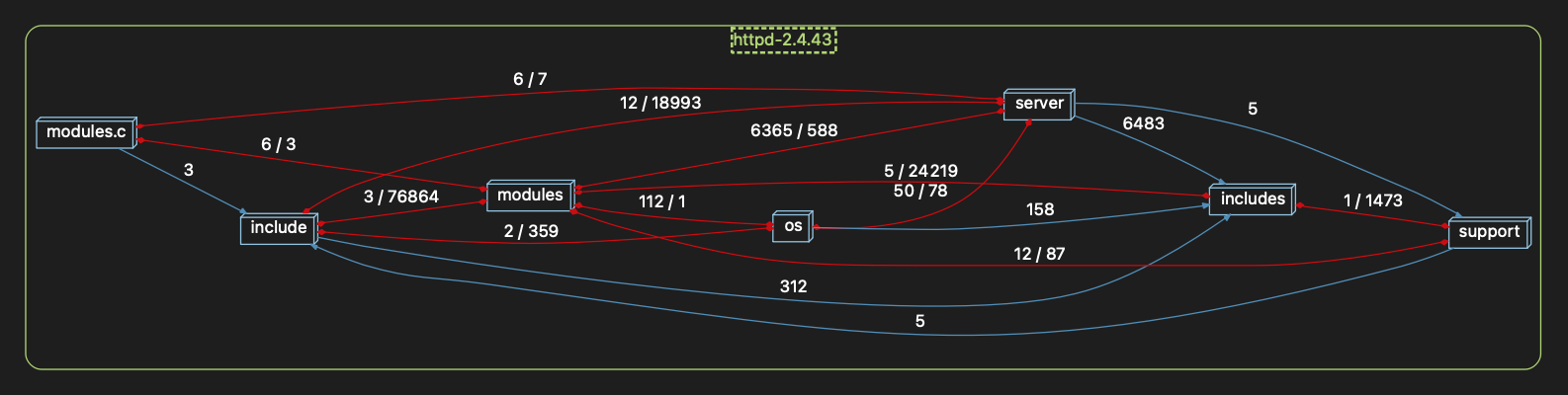
I’m looking at the Apache web server source code. When I choose the Dependency Graph based on Directory Architecture, I get this pretty nice looking graph:
But check this out… I’m interested in server code… so I open up “src”, and the result is… well it’s a bit messy:
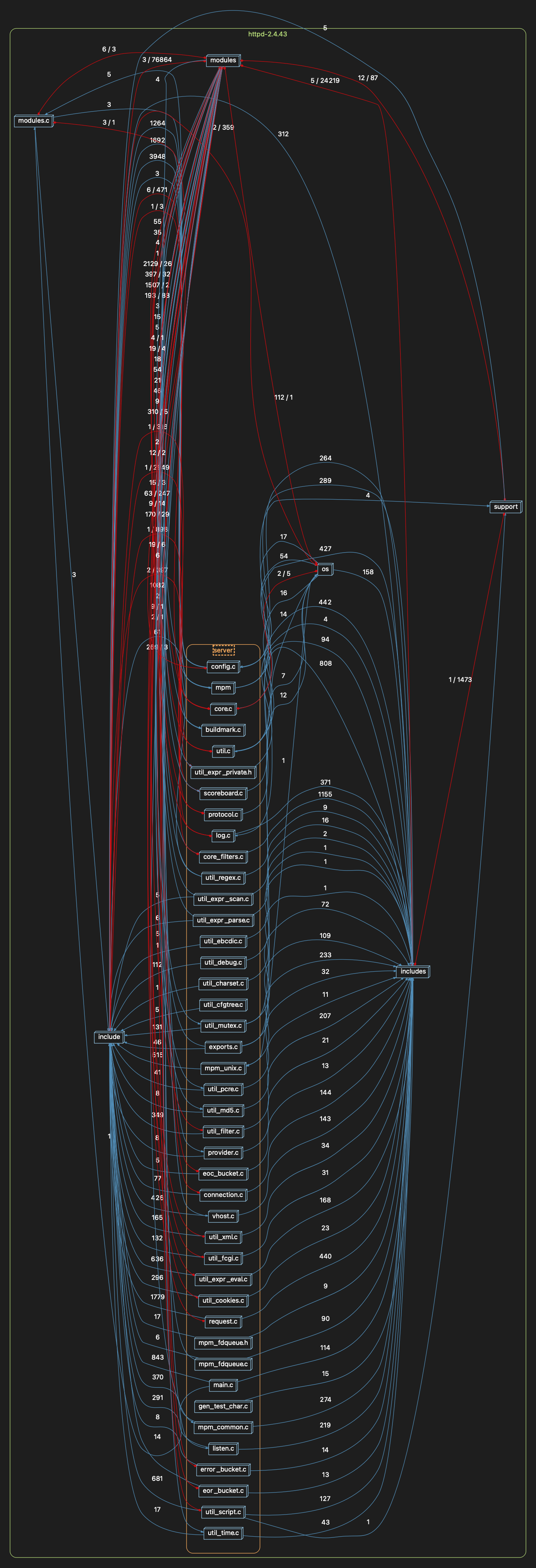
The basic problem is that this directory structure was built for building not for drawing informative graphs about the source code.
Fortunately, I don’t have to accept this state of affairs.
Looking at the source in “server”, I see some groupings… things like “util_*”, and “error”, and “mpm”.
So what I’m going to do is duplicate the built-in Directory Architecture and then add a little “human” flair to it…. and I can do this without modifying any source code or messing up my build system.
The end result will be a graph that looks like this when I dig into “server”:
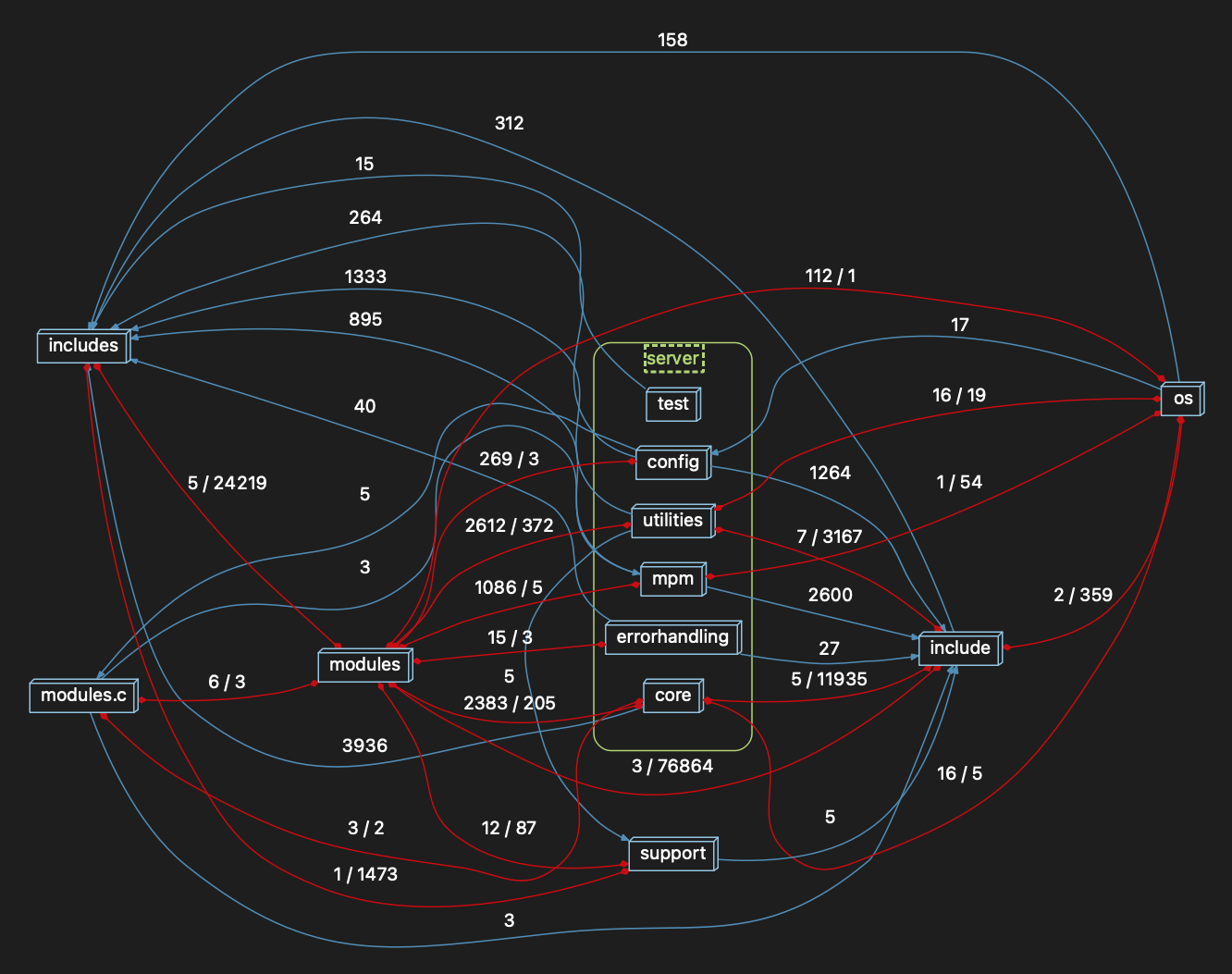
That’s a lot better! And it only took me a couple of minutes plus I learned a bit about the code whilst doing it. Win… and win!
How I Did It (and you can too!)
It was simple – here’s an overview:
- Duplicate the automatically built Directory architecture. I’ll call it “Directory+Human”
- I’ll then go into server and add these architectures “config”, “mpm”, “errorhandling”, and “core”.
- I’ll drop the appropriate .c/.h files into their architectures. This doesn’t change anything on disk or in the project – it’s just virtual re-organization.
Here’s what the Directory architecture looked like prior:
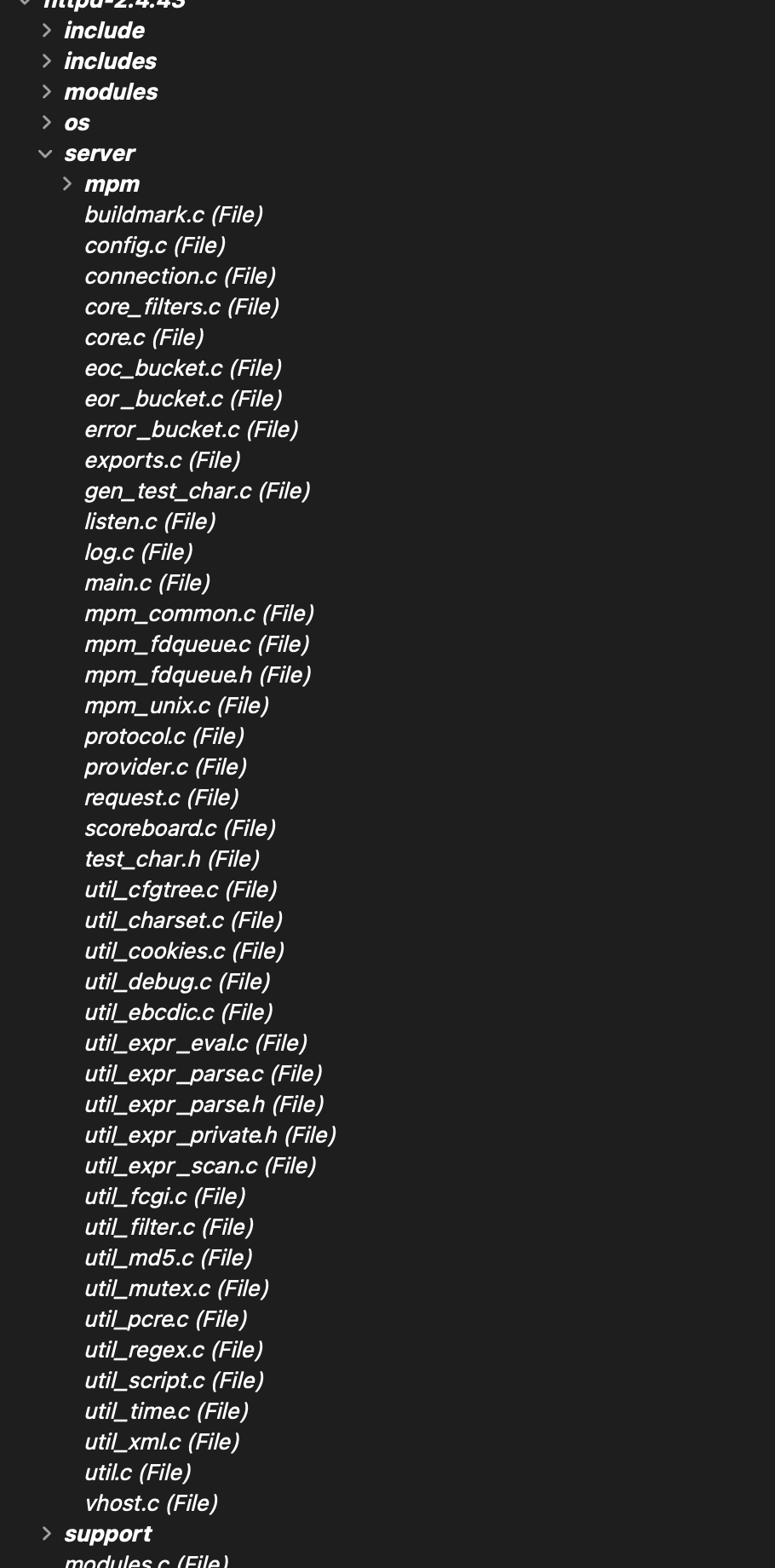
and here’s what it looks like after I virtually move files to where they go in my new architecture scheme:
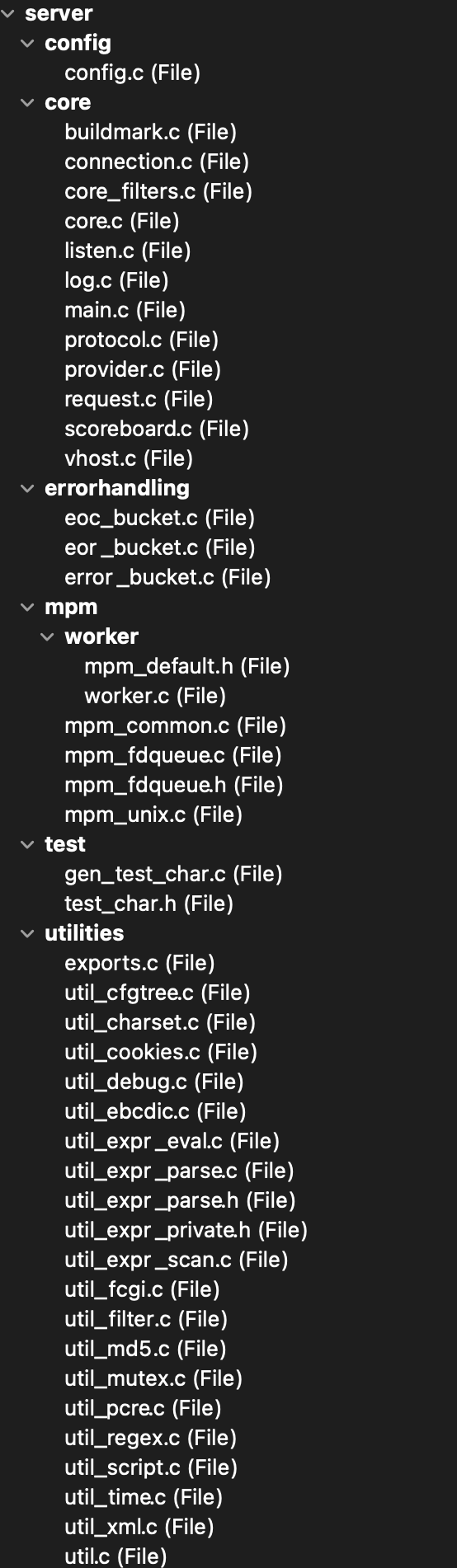
Pretty simple!
What would I do next? I might break up “util” a bit and subdivide it into “expressionparsing”, “debug”, and “importexport”.
Summary:
I don’t have to accept what past developers gave me as a way of thinking about and organizing the source code they left me. I can, without messing up the build or SCM systems have it “my way”, or more specifically in a way that helps me draw, measure, analyze and understand this source code better.





