

Hi there, and welcome to Understand.
In this short tutorial we’re going to go over how to write your first custom Codecheck in Python.
The Scenario:
Your boss tasks you with figuring out how tied your C++ code base is to the ‘#pragma’ compiler directives. He/she wants to know this information because pragmas can change compilation details that aren’t otherwise under a developer’s control. They can also vary from compiler to compiler, as they’re not part of the grammar of a programming language, but rather compiler-specific.
The Solution:
Let’s write a short Python Codecheck script that can solve this issue for us quickly and easily!
But wait – why should we write a Codecheck rather than just performing a Find in Files or Grep-style search on our project? Well, these types of searches will pull up comments including the word “pragma”, and entities such as functions that may be named “pragma” as well. With Codecheck there’s a better way – we can refine our search to solely look for preprocessor directives, and we can even grab the directive name to later report.
Ok, time to get started. First, create your script file and give it a .upy extension. We need to ensure that Understand can find it, so save it to your ‘SciTools’ directory. Here are a few of the locations it could be, depending on your OS:
Windows:
• C:\Program Files\SciTools\conf\plugin\User\CodeCheck
• C:\Users<USERID>\AppData\Roaming\SciTools\plugin\Codecheck
Mac: (note – the plugin/User/Codecheck directory will need to be created)
• ~/Library/Application Support/SciTools/plugin/User/Custom/
Linux: (note – the plugin/Codecheck directory will need to be created)
• <path_to>/SciTools/conf/plugin/User/Codecheck
• ~/.config/SciTools/plugin/Codecheck
Now we’re ready to get started writing our script.
At the top of the script, let’s set some global variables to store the violation messages we need:

Now there are some functions we need to add to provide some information about our check to Understand:
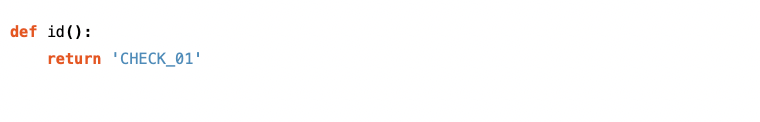
This function will return the unique identifier for this check. Make sure this is a unique string that isn’t used anywhere else.

This function will return the short name of the check. Just make this a phrase or word that reminds you what the check does.

The above function will return the string you provide and display it in the ‘checks selection’ interface within Codecheck. Here you can provide a more in-depth explanation of what your check does, any notes or exceptions to the check, and even simple code examples that show how the check should behave.
Now that we have our set-up functions out of the way, let’s start telling Understand where to look and what to look for in this check.

The test_entity() function is another required one, and tells Understand what file types to check if this check will be run on a per-file basis. Since we want to check all source files in our C++ project we’ve provided both ‘code’ and ‘header’ files as the argument.
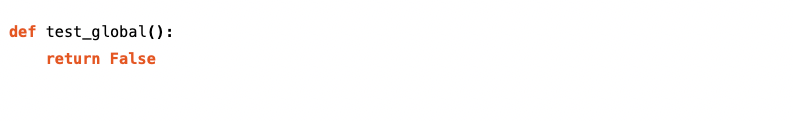
This function is optional – we would set it to return True if this check should be run on the entire project regardless of which files are selected (say, if we wanted to count the total member function declarations). This function should only be set to True for project-level checks, otherwise it can be set to False or omitted from the script entirely.
One really useful feature with Codecheck scripts is that you can set configurable options with your custom checks. For this script, I’m going to add an option to show the total ‘pragma’ directive count for each file where at least one is found. To do so, I’ll add the following optional function:

This function uses the ‘check’ entity to tell Understand we want to configure a checkbox for displaying the file count. You can also configure options for integer inputs, text inputs, and radio button choice selections. In this case we want to go with a checkbox to give the user of the check a simple ‘yes/no’ choice. The first argument of this function is the name of the option (and how we will access it later), the second argument is the text displayed next to the checkbox in the GUI, and the third argument is a Boolean value allowing us to set the checkbox’s default to checked (True) or unchecked (False).
Next, let’s set the language we’d like to run the check on.
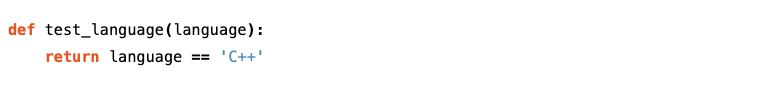
The above function is passed the ‘language’ entity which comes from the project configuration, and will run the check only if the project contains C/C++ code.
Ok, now we’re finally ready to get to the heart of the check – the check() function! This function runs the actual Codecheck and returns violations if any are found. It potentially has two parameters –
- If the check is designed to run against the whole project at once, just pass the ‘check’ entity
- If the check is designed to be run on each file, pass both the ‘check‘ and ‘file’ entities
In our case, we designed our check to run on a per-file basis, so we’ll define it the second way:

Now, the rest of the code provided below will be inside of this check() function, so keep in mind it will be indented to keep it in-scope.
To find pragmas for this check, we’re going to have to use the lexer. This lexer is a lexical stream generated for a file entity, and is made up of individual lexemes (or tokens) that can be accessed or iterated over.
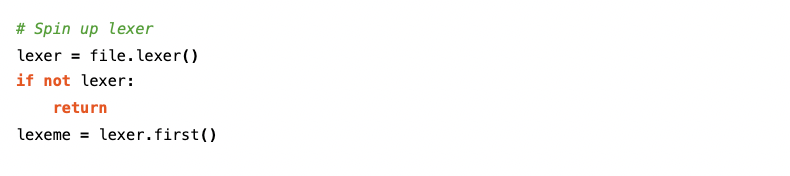
The above code generates the lexer for each file, verifies that it was indeed generated correctly, then assigns the first lexeme in the lexer to the variable we’ve named ‘lexeme’.
Next we’re going to initialize our pragma counter to zero:

Now we can iterate through our lexemes and look for pragmas like so:

The above loop continues until there are no more lexemes in the file, checking whether each lexeme’s text is equal to “pragma” and has the token type “preprocessor”. If the lexeme in question matches those conditions, the next lexeme that is not whitespace or a comment is grabbed, telling us what pragma directive we’re looking at, and is assigned to the variable ‘nextLex’. Then, the violation() function is called on the ‘check’ entity we passed into the ‘check’ function and flags a violation for us in the GUI. The first argument in the violation() method is the entity we’re flagging. Since pragmas are not considered entities, we pass the entire file as the entity instead. The second argument is the file we are in. The third argument is the line the violation begins on, and the fourth argument is the column that it begins on. Finally, the fifth argument is the error message we’d like to display with the violation. You can see that ‘nextLex’ is passed as well to substitute the ‘%1’ in the global error message we created.
The last thing we do before moving on to the next lexeme in the file with ‘lexeme.next()’ is we increment the pragma count for the file.
Once we’ve exited our while loop, we need to check whether the file count should be displayed, and if so, flag another violation:

The above code accesses our ‘file_count’ option with the lookup() method, and if that option is checked and the file has at least 1 pragma, the second violation message is displayed showing the pragma count. Notice that since this violation is done at the file level, line and column values of 0 are passed as the location of the violation.
Great, we’re officially done writing our first Codecheck!
Here’s how the check will appear in the Codecheck Selection GUI:
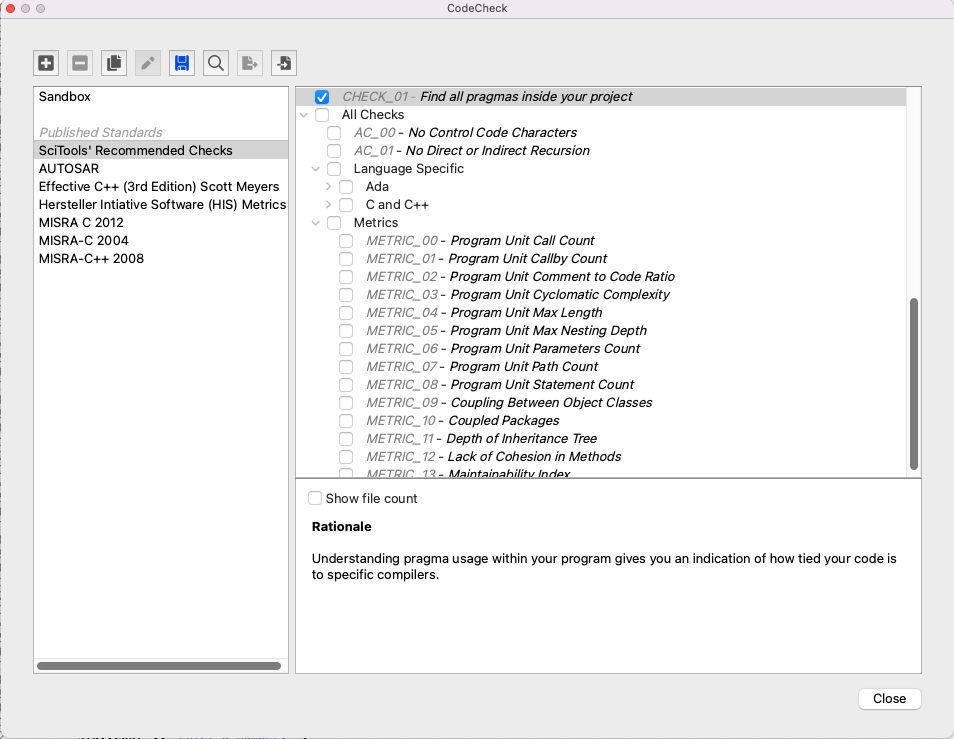
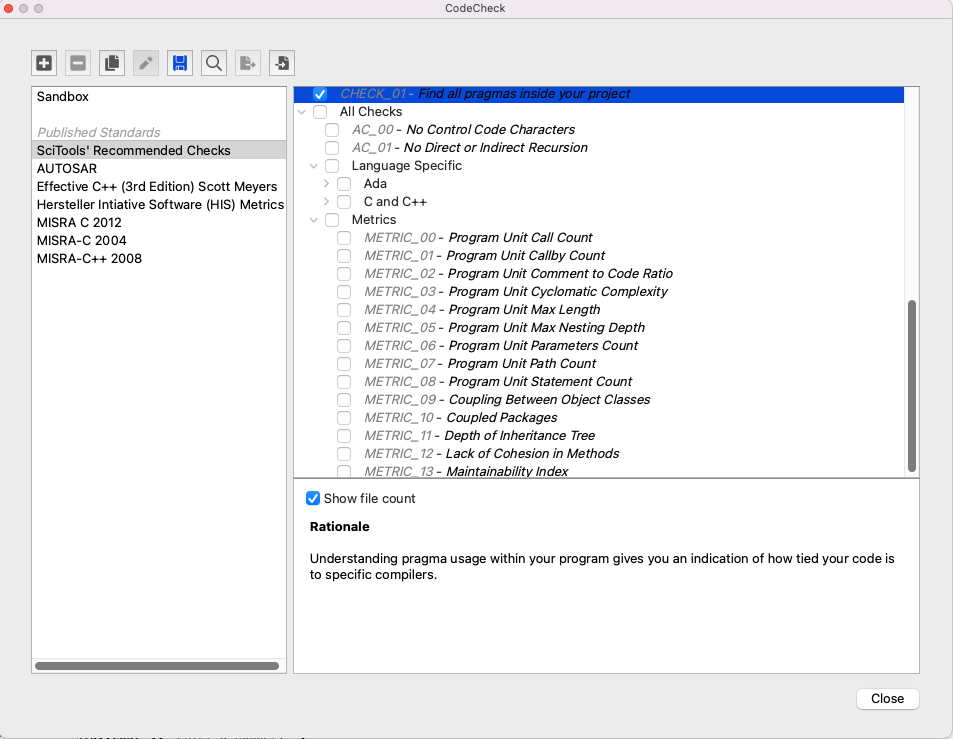
Once selected or highlighted, your check will display any options you’ve configured along with the detailed description of the check just below it:
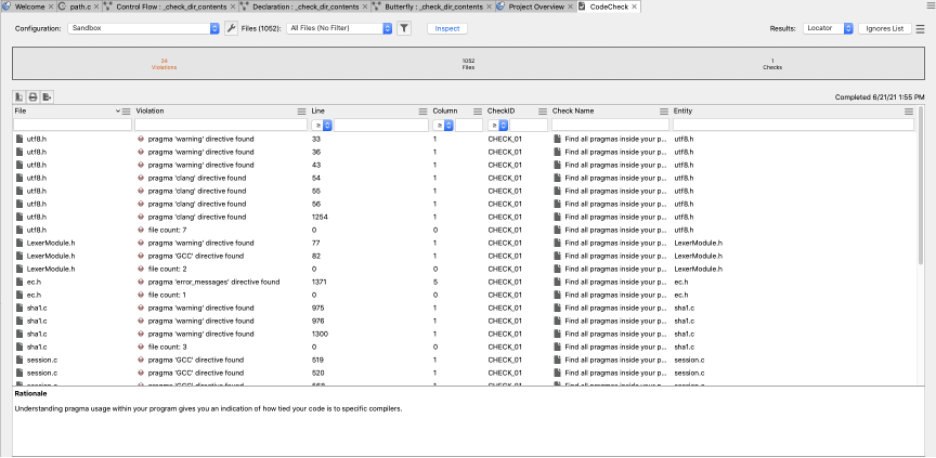
After we’ve run our check, this is how the violations will be displayed in the Locator view mode:
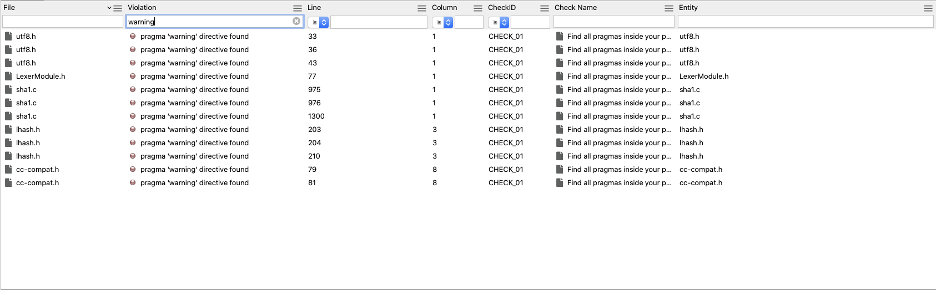
From here we can narrow down our violations by typing ‘warning’ in the violation text box to see how many ‘pragma warning’ directives we have in the project, or we can type ‘file count’ in the same text box to see all files where we found pragmas along with their total pragma count:
Congratulations on writing your first Codecheck!
Now that you’ve written this script, all that’s left to do is to share the script and configuration with others on your team using version control, or export the results to a .csv file and send it over to your boss. Consider the day saved.
Cover Photo by Kai Pilger on Unsplash





