
Abstract: Part 4 of a 5 article series about using Understand to analyze how a CMake-based project has changed over time. This article focuses on creating a trendline of changes to avoid the artifacts caused by non-linear history.
This is the fourth in a series of articles exploring a set of databases for different timepoints in GitAhead. The first article described how to analyze source code retrieved from Git. The second described automatically creating the set of databases. In the third article, we ran CodeCheck on those databases to generate trendlines and explored graph artifacts. Here is one of those trendlines again:
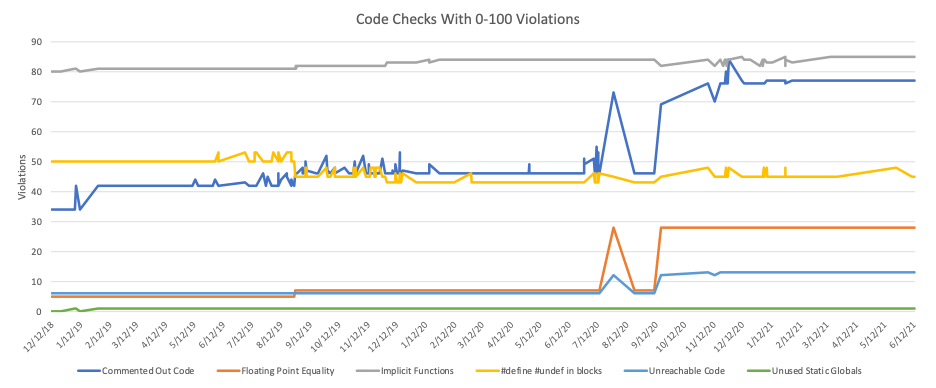
As described in the previous article, the spike around August 2020 comes because a commit on 7/29/20 updated a library, adding code and violations. The next chronological commit, on 8/20/20 had branched before the 7/29/20 commit so it did not have the additional code and violations.
Suppose I want to know how the commit on 8/20/20 really changed the CodeCheck violations? How can I get that information?
CodeCheck Options
There is a CodeCheck filter option to only run CodeCheck on the changed lines (see this article). In effect, this runs CodeCheck on any files that have changed then filters the results to show only the violations on changed lines. So, it’s close to the numbers I’m interested in, but falls short in two ways. First, it can’t tell me if violations have been removed. Second, it can’t detect if the violation existed both before and after a particular line changed. So, the final count is violations added plus violations not fixed.
However, I have the full CodeCheck results for many time points. So, I can compare the summary counts from one time point to the parent time point to get a difference. This approach may still fall short. It assumes that the only differences between two databases are due to the changes Git reports. It can also obscure changes like “one violation was removed and a new violation was added somewhere else” which would show a net change of 0.
Still, using the numbers I already have saves me from re-running CodeCheck and it provides an estimate of net change that includes removed violations.
Are you my parent?
Then, I need to know which of my 200+ databases is the most appropriate parent for the 8/20/20 commit. Here’s the information from GitAhead.
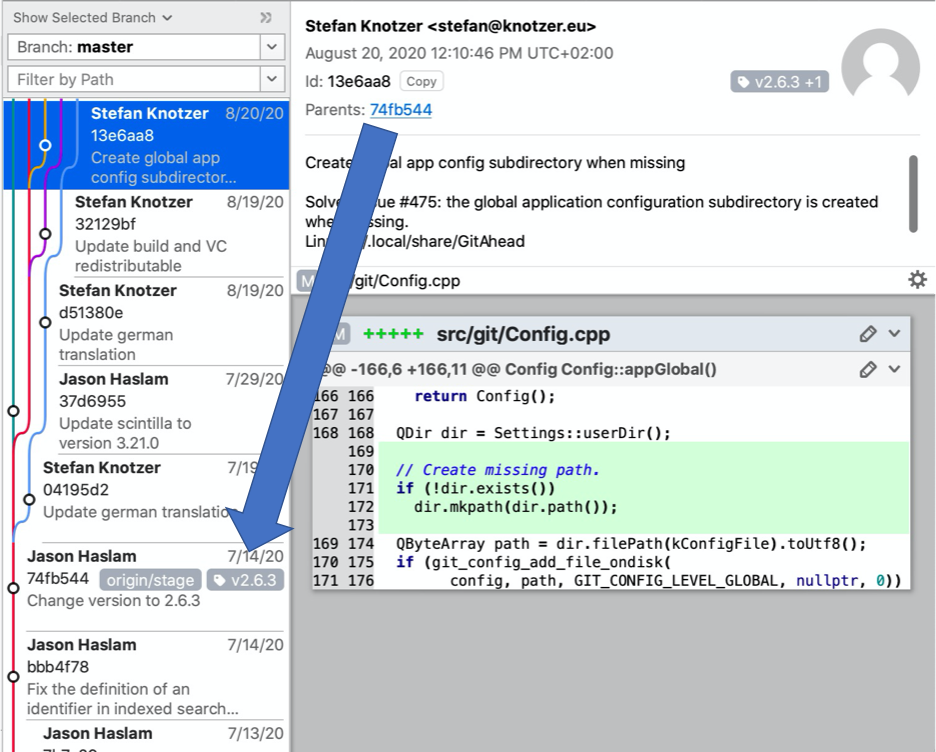
So, I need the commit on 7/14/20 with ID 74fb544. The problem is, I didn’t make a database for it because it didn’t include any changes to code files. I do have a database for bbb4f78. Since no code file changes occurred in 74fb544, using bbb4f78 should not be a problem.
It turns out that there really are fewer violations in the 8/20/20 commit than the 7/14/20 (bbb4f78) commit:
- 72 fewer definitions in header files
- 3 fewer #define #undef in blocks
- 72 fewer unused functions
- 25 fewer uncommented variables.
But, looking at the commit, the numbers don’t make sense. How can adding 3 lines of code in a cpp file impact definitions in the header files? Comparing the output logs between the two commits shows that one file, dep/openssl/openssl/include/openssl/pkcs7.h, is included in bbb4f78 but not in the 8/20/20 CodeCheck results. Most, if not all, of the violation differences seem to come from that one file.
One of my assumptions has already proven false! The Git changes are not the only differences between the databases. Still, using bbb4f78 gave a better estimate than using the chronologically adjacent commit on 7/29/20. So, how much can I automate the search for the best parent?
Automating the Parent Search
Git knows what all the parents are, so the first step is retrieving that information from Git in a convenient format. I used this command:
git log --format="%h %p" > ~/projects/debugOutput/gitahead_pars.txtThen I can copy and paste the information into my Excel spreadsheet (see the second article) on the sheet that had all the commits (conveniently named “All Commits”). Now, I need the information on the excel sheet with the commits I have databases for. I can use this formula, where B is the column in both sheets that has the short commit hash, and the column F (the fifth column over) has the (first) parent commit hash.
=INDEX('All Commits'!$B$2:$F$381,MATCH(B2,'All Commits'!$B$2:$B$381,0),5)
Next, I want to search for the parents’ commit hash in the list of databases I have. But, I’ll need to update parents occasionally, like with the 8/20/20 commit using bbb4f78 instead of 74fb544. So, I’ll copy the values from the parent column into column F of my “Selected Commits” sheet. Column G will report the row of the parent’s database using this formula where the plus 1 adjusts for the header.
=MATCH(F2,$B$2:$B$233,0)+1
With just this much effort, I’ve found parent databases for 119 of my 204 databases.
The Non-Automatic Parent Search
Finding 119 parents with my automatic matching isn’t bad. But, what to do with the 85 left over. I’m not a hundred percent sure how to decide what the best adoptive parent will be. So, nothing for it but to do it by hand the first time so I can work out an algorithm for the next time.
The first (most recent) database is for commit b774160 on 6/13/21. The parent is 8efe5d6, This is how it looks in GitAhead.
Yikes, 8efe4d6 is a merge commit. How am I supposed to pick a parent now? If I pick one branch, then the differences I calculate will be from the current commit and all the commits on the other branch. If I want good numbers, I’m going to have to create a database for 8efe4d6.
Summarizing 85 commits later, I’m able to find adoptive parents for 57 commits and the remaining 28 orphaned commits will need parents created. Note that those are numbers of orphaned commits. Some commits have the same parent, so the number of parents examined is actually smaller.
Rules for Finding Parents
Using my manual scrutiny, I’ve determined some general rules I’ll use to automate this process:
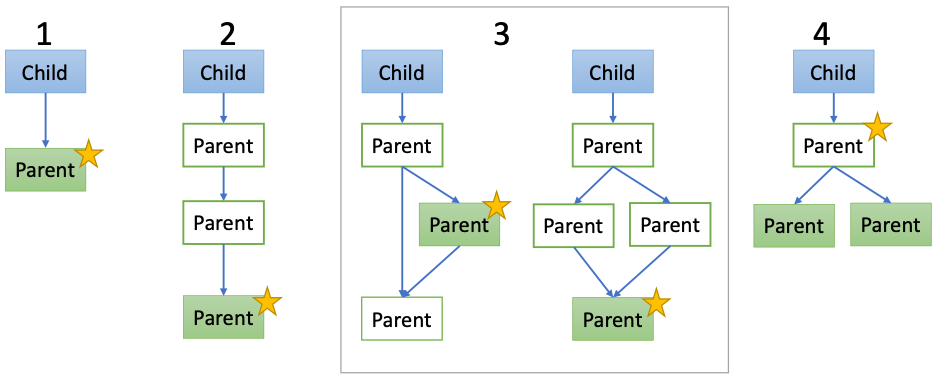
- The simplest case: the true parent is found. Use it.
- A simple case: the parent is not found, but the chain of parents has no branches (no merge commits), so follow the chain until a parent is found.
- A harder case: the parent is not found and there are branches in the chain of parents. But,
- there is a single found parent before the first common parent or
- the first found parent is the same for all branches. Then, use that found parent.
- The hardest case: the parent is not found, there are branches, and the found parent is different in at least two branches. A new database must be created for the parent.
Visual Results
With no alternative, I created the missing parents following the steps in the second article. After creating my missing parents, I need an Excel formula to quickly calculate the diff between the current commit and its parent. I have the raw numbers in a sheet called “Selected Commits”. I’ll create a new sheet called Selected Commit Diff for the difference calculation.
The first few columns of the sheet are direct copies (B2=’Selected Commits’!B2). The diff columns need to take the raw value and subtract the parent value. This is the formula:
='Selected Commits'!R2 - INDEX('Selected Commits'!$I$1:$AI$233,'Selected Commits Diff'!$G2,10)
The first part grabs the value at the current commit (row 2, column IR). The second part (starting with INDEX), gets the parent’s value by looking at the full table and using the row of the parent (stored in Column G) and the column offset (10 in this case to get to column IR). With some conditional formatting highlighting positive (red) and negative (green) numbers, the spreadsheet looks something like this:

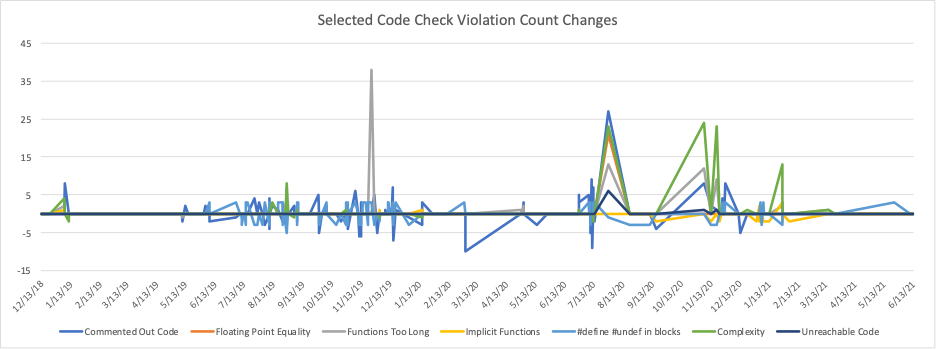
At this point, I’m satisfied. Spreadsheets with colorful formatting make me happy. But, I did mention trendlines, and I’d hate to disappoint. So, here’s a trendline for CodeChecks whose differences are in the range -15 to +45.
Result Details
The chart has an unusual spike in functions too long at a commit on 11/24/19. Is this another artifact like the 8/20/20 pkcs7.h one described above? This is the commit:

The commit diff doesn’t reveal any obviously added functions. Instead, the main change in code files is additional Q_OBJECT macros. So, the increase in functions that are too long is probably from a function in the macro expansion of Q_OBJECT.
This is confirmed by looking at the saved CodeCheck Tables. Comparing the list of functions that violated the check, there are 38 more results in the 11/24/19 commit compared to its parent and all of them come in pairs of Class::tr and Class::trUtf8. So, even with this rough estimation, the graph can reveal real changes.
Other spikes in the graph seem to affect many checks at the same time. They likely represent points where a submodule or library was updated, causing many changes. The first spike, for instance, comes from the 7/29/20 commit mentioned at the beginning that updated the Scintilla library.
In the next article in this series, we’ll explore what we can learn from this about each of the different editors of GitAhead.





