

I’ve spent a career writing tools to help people succeed with legacy code. So, yes, I’m going to include tools in some of these techniques. However, all the tools in the world won’t help if you don’t follow one rule…
Only Make Changes to Legacy Code that You Understand
Success with legacy code requires humans to understand what they are changing. All 9 of these techniques I will cover revolve around how to help you, as an engineer or engineer manager, follow The First Rule of the Legacy Code Fight Club:
Only Make Changes to Legacy Code that You Understand
That rule is so important I gave it to you TWICE!
Success with legacy code boils down to making changes to code you understand. You predict the behavior of a change, make the change, and test the behavior. Rinse and repeat.
Doing anything to legacy code without a clear understanding of the code is dangerous to the functioning of the software and possibly to its users.
Some knowledge of your legacy code comes from humans – either by conversation, reading what they wrote as they worked with the code, or from your own memory. That information will be helpful but may be out of date and suffers the errors all human communications have. So sometimes tools are the only things with actual answers – or understanding of the source code you are about to change.
Just like as you grow older, you get “better” ( experience, proof of success, knowledge) you also sometimes have “issues” like not understanding new tech and visiting doctors more. Legacy code shares all those traits. Legacy code is valuable… and if you are maintaining it, it’s your role to keep and enhance that value. It’s worth doing. And it is especially worth doing right.
Legacy code often differs from its suggested alternative by actually working and scaling.
Bjarne Stroustrup
Here are 9 systematic approaches that will help you UNDERSTAND your legacy code, and thus have a better shot at maintaining it in the manner it and your users deserve:
- Retention FTW. There is no substitute for talking with the person who wrote the code
- Encourage, reward, and prioritize legacy code discussions
- Prove understanding of legacy code by writing tests
- Stop digging a deeper hole… keep those tests up to date
- Prove understanding of legacy code by correct hypothesis before changing
- Prove understanding of legacy code by architecting it
- Prove understanding of legacy code with Notes and Writing
- Use automatic knowledge to multiply your brain power
- Try to say no (the right way)
———-
1. Retention FTW. There is no substitute for talking with the person who wrote the code.
She wrote the code you are trying to sort out. Sure would be nice to have a chat, wouldn’t it?

If she still worked with you, you could talk with her. Even if she’s doing something different (everybody moves on), you’d still have access to her intel if/when you need it.
While it seems a “given” that software engineer turnover rate is “10%” or that they will have a new job every “2 years”, these stats are an average, not a goal.
Why not be above average? Why accept that 10% will leave every year? Be better at keeping your good engineers!
Perks like lunch, snacks, and drinks, are a minimum. And some, like ping pong or massages, are just a distraction.
The real key is autonomy – over what they work on, how they work, when they work, and as you’ve probably encountered in the past couple of years – where they work.
Followed by respect and dignity. Nobody likes being yelled at. Nobody likes having their chain jerked. And nobody likes being managed by idiots. Or having their ideas and contributions not valued or considered.
To retain good people, be someone good people want to work with.
The final pieces are comfort and life quality while at work. For most software engineers that means a quiet place to focus, few interruptions, and amazingly fast computers that build quickly and show code on crisp, clear monitors.
Trust them – they know what works for them. In “Just say Yes” I discuss how it’s cheaper and better to believe and trust your engineers – especially if retention is a primary goal. And it should be!
Quit saying you value retention. Start acting like you do.
p.s. high retention workplaces are happy places. Be happy!
2. Encourage, reward, and prioritize legacy code discussion

He knows things. And he uses a Mac.
Imagine you are kicking butt on retention. People stay. They love working with you. This is super handy if they are also working on the code. If they aren’t, the next best thing is that they talk to those that are.
Formally give them permission and the time, space, and schedule leeway to spread their knowledge. This can be in informal ad hoc question and answer sessions, but also in formal presentations about the legacy code.
At SciTools we’ve had lunchtime presentations about legacy code by our senior engineers. They discuss architecture, design intents, how to use, code standards, and answer questions.
Most of the magic, however, happens in ad hoc chats. In my experience, the problem will likely be getting the new engineers to be willing to bug the old ones. They are nervous. They don’t want to waste the senior’s time or look dumb.
So they need permission for both. And guidance on how to do it. Just dropping by. Not so cool. Requesting some time, and maybe with a background topic is the way to do it.
|
“Hey Jason, do you have some time this afternoon to discuss some changes I’ve got to make to the Understand editor to support showing post-it like annotations?”
They got senior by being good. Their time is valuable. So it is a balance. Preparing for discussions as the learner, and letting them know in advance what you hope to learn, is the ticket to productive learning that values both parties’ time.
In summary… give your people permission and time to talk. Teach them how to do it efficiently.
3. Prove understanding by writing tests of software you are about to change
“To me, legacy code is simply code without tests.”
― Michael C. Feathers
Working Effectively with Legacy Code
Our goal is to only make changes to legacy code that we understand. How do we know that we “understand” the legacy code? Write a test of it.
If it already has tests, then understand them. That might be easier than understanding the function.
As an example, if you are tasked with changing a function that adds two azimuths, adjusts the azimuth for the wrap effect at 360 degrees, always make 360, zero due to convention… how do you know it works?
Write tests. Write a unit test that has a set of known azimuths and the right answers. Drive the function, and ensure it returns correct answers.
The key part of this is that you understand what the function is supposed to do – enough to write a test for it.
What if you can’t?? Is that a function you should change? Or is more learning required? More understanding?
Here are some useful links for writing “tests” for code you want to maintain:
https://michaelfeathers.silvrback.com/characterization-testing and https://understandlegacycode.com/approval-tests/
There is no “perfect” way to do it – as long as you are improving your understanding of your legacy code, you are doing it right.
Problem: Can’t get your managers to sign off on this? Maybe you can’t change the code, or there just isn’t time?
A variant of this is the rubber duck explanation. Explain the TEST of the function to a rubber duck so that it could understand it. If you can… maybe you understand it enough to work on it. Remember, you are explaining the TEST, not the function. That might be almost as effective as writing the test itself. In any event, even if writing tests this is a very good place to start before coding them.
4. Stop digging a deeper hole… keep tests up to date as you change code

First… stop digging…
Technical debt piled on past technical debt just becomes more tangled, indecipherable, and dangerous.
Code reviews should insist that changed code comes with tests.
Branches should have tests supporting them.
Reject pull requests that do not include tests.
The tricky part here is “what change deserves a test”.
But this really isn’t tricky at all. All changes deserve a test – or a definitive “not needed” determination because existing tests cover the change.
A general rule. If the requirements changed, tests are certainly required.
Tip: Tools to ensure tests happen
How do you know what code are tests, or that code has tests, or especially that changed code has changed tests? A simple approach is to indicate them in a comment. For example in C code:
// #testfor class method AddAzimuths <date>
As an aside our tool “Understand”’ lets you mark comments that way to track lots of different things about your code. Or if you don’t want to mark your code up with comments, it offers something called “Annotations” which are persistent with the code even as it changes but are not stored with the code.
Using simple tools you can find tests, or find out there are none and that you’ve got some work ahead of you. And during code reviews or pull requests you can know that code that was changed has tests that were added or changed. And if not, Find out why!
5. Prove your understanding with correct hypothesis BEFORE you make changes
One of the more popular articles on our blog is “https://blog.scitools.com/the-science-of-debugging/” by our senior engineer Jason “Hack” Haslam.
In it, he proposes that debugging and the scientific method share the same process. He applies the same approach when he refactors or maintains legacy code:
– Start with a Hypothesis of What The Change will Yield in Testable Behavior / Outcome
This serves as a “prediction” that you can test against.
– Make your Changes
– Run your Tests to verify your Predicted behavior.
Start with small predictions. As they come true, your trust in your understanding of the legacy grows, permitting larger and larger predictions (bigger and bigger changes).
Going back to #3… what did we start with? A prediction in the form of a test!
So what this really boils down to is after you write tests of current legacy code… start your changes by thinking about and writing tests for changes you want to make.
Start small and as your tests succeed, so does your knowledge of the code, meaning it is safer to go for bigger changes – but only ones you can design tests for.

6. Prove you understand code by Architecting it

Architecture takes the generic and makes it understandable. Your house has rooms. And doors. And windows. We “architect” our house by having “public” and “private” rooms. We get more specific, and soon some rooms we call “Bath Rooms” and others “Living Rooms”. This helps us understand the house, use it, live in it, and even know its size. For instance a 12-room house, verus a 6 bedroom, 4 bath home. The more “architected” our description the more we know about the house.
Software, under maintenance, is a house long past what the “architect” originally built. The “architecture” is what it is, and what those who work on it think and say it is.
If you read the quotation above what it boils down to is that the ACTUAL as-built architecture comes from the source, not from being imposed by some grand scheme when the software was first conceived.
In our Understand tool, we implement bottom-up architecture via “tags”. As you, and other, developers “tag” the code, information about the code that can’t be had from reading it is gathered and transmitted – much like when we do neighborhoods in towns or rooms in our house.
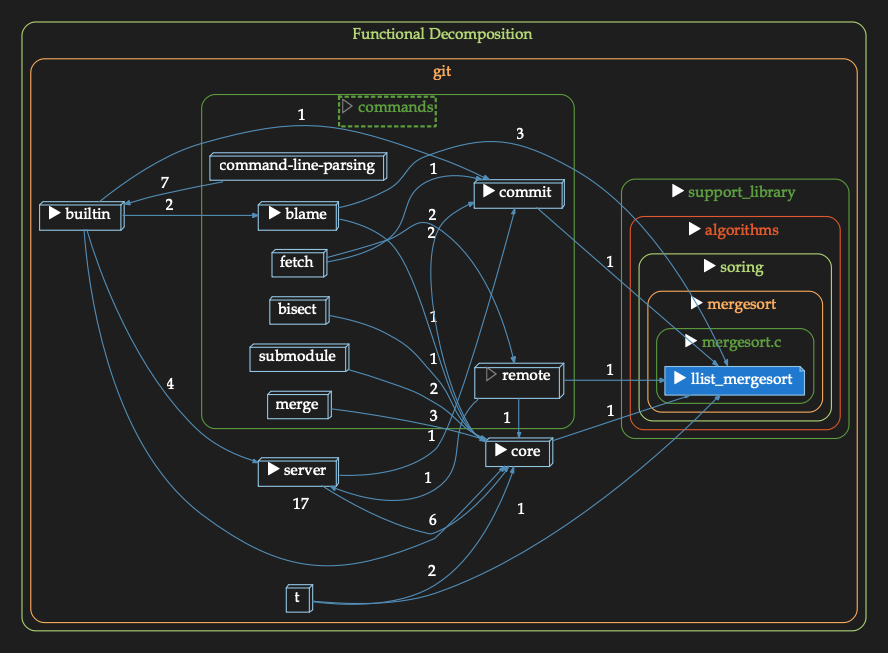
For a more detailed overview of using “architecture” for comprehension, see my article on “Making Sense of GIT”. In summary, I start with this “understanding” of GIT, which of course is useless:
And with a bit of thinking, code reading, and more thinking, I end up here a few hours later:
I studied the code with an eye toward what the “rooms” were. I learned and tagged what I learned. Now, anybody else using this architecture benefits. I gained knowledge. I transferred it forward with a simple architecture that others can use as well.
This works solo but becomes especially powerful when everybody contributes from the bottom up.

7. Prove you understand code with notes and writing
About 15 years ago (maybe longer) I visited a large customer of our Understand tool. They had generated and printed immense call graphs using Understand and large plotter printers, hung them on the walls of a very large room, and used ladders to place large post-it notes with information about the functions/modules in the call graph. Some were actually green bar printouts taped to the functions, some were post-it notes, and some were handwritten notes on the edges of the graphs.
I thought “neat”… how can I do that in Understand and make this easier (and require no ladders)? And “Annotations” were born.
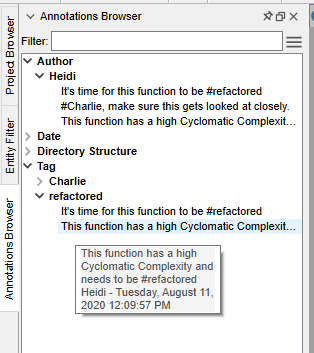
Annotations are things you learn about source code. They stay with the source code even when you change it (even renaming). You can “annotate” a function, a file, a line of code, or an architecture.
They don’t clutter up the source view. They are comparable to notes/comments in Excel, Word, or Google Doc documents.
Annotations can be handwritten notes, hand-typed notes, photos of whiteboards, or embedded PDFs with papers about the algorithm you used… any source of information commonly available can be annotated and kept with the associated source.
Become a compulsive note-taker. As you read code, maintain code, and TALK ABOUT CODE WITH COLLEAGUES, help current you, future you, and future others by noting what you learned:

1. Update in-code comments to reflect reality. Or remove them if they mislead.
2. Write notes… maybe even on PAPER about what you are learning as you maintain/read/refactor code. Index them. Or use them as Annotations.
3. Post TIL (Today I learned) notes in your team comms… slack, discord, whatever…. “TIL that you should not assume double precision in the Azimuth calculator, because it’s actually single due to 15 years ago that was all the onboard computer could do”. This can also be an annotation.
Note – positive TILs are good to do. Not everything is a failure. Sometimes your software can do awesome forward-thinking things – document those too!
4. Write up what you know about architectures, functions, and classes. Annotate it. Or put it in shared storage where a search will find it. You learn by writing and others learn from what you learned.
5. As you work on code, write code, read code… ANNOTATE what you learned.
Consider that if you don’t have notes, or can’t write what you know, about a piece of legacy code… MAYBE YOU DON’T UNDERSTAND IT WELL ENOUGH TO CHANGE IT?
8. Use automatic knowledge to multiply your brain power
Most humans can remember 7 to 10 things. Some techniques, like memory palaces, use chunking 7 to 10 things up into 7 to 10 rooms, and so forth, to greatly expand that – to a hundred or more.
Don’t bother though… ALMOST ALL SOFTWARE IS TOO BIG FOR YOU TO “REMEMBER”
You need help.
This modest function, not a particularly important one, in GIT, is used 1269 times, in a number of different ways. Change it at your peril!
Sure, if you change a parameter the compiler will tell you. And Grep will find text for you. Use them if you must, but tools like Understand (and others) were written to take away the burden of knowing and just show you.
If a change you make has side effects – and side effects are the purpose of change – you will have to explore everywhere impacted by the change.
Ideas:
– use a tool (or tools).
– use architecture so you can triage important areas first. Look at side effects in the “SendMoney” architecture, then maybe the “PrintDebugInformation” architecture, time permitting.
– Use architecture to keep track of where you’ve explored. “Checked/Not Checked”. Super easy. Annotations can be used similarly.
#8 is how our engineers use Understand day in and day out. It’s the bread and butter, even if not sexy.
For more information on this see my blog article “Hyper X-Ref in Understand”.

9. Try to say no (the right way)
Having the gumption to “say “No” is a skill. Doing it in a way that keeps customers happy, and good relations with colleagues, and your job prospects, is an art.
Some rules for saying no:
1. Never personalize “no”. Or anything else for that matter. “No, you are always bringing stupid ideas” isn’t the way to say no.
2. Back “no” up with real provable data. “This change will require 30 new unit tests, touch 4 engineers, will take at least 3 months partly due to effort and partly due to other scheduled things. It touches 20,000 lines of code, and impacts 300,000”. Don’t exaggerate. Be optimistic – with most software that is scary enough.
3. Offer a no that is a “yes”… “it’s time to refactor this, how about instead of 3 months we take 4 and just re-write it. We can use lessons learned, more experience with this platform, and a better understanding of where we are heading to make it better”.
Ultimately, your fate will be in other hands. Give them the information to make good decisions.
And then do your best, don’t burn bridges, and always be honest.
Honesty in action.


Thanks for getting this far!
What do you do? Send me how you work with legacy code. I’ve been around for a good while but I definitely want to keep learning! [email protected]





