
Abstract: Understand looks and acts a lot like an IDE, but don’t be deceived. The real power of Understand comes from the way it represents your code and the solutions you can build on top of that paradigm.
In one of my first computer science classes, the professor taught everything in Emacs. I was convinced the whole point of using the Linux and Emacs was to mimic movies where smart characters typed frantically and had lines of text scrolling across the screen. Thanks for making coding seem even more cryptic!
Now, X years later, I use a terminal daily. I won’t deny that some of the reasons I use it are because it reminds me of movies and makes me feel smart and cool. But there’s more to it than that. Now that I understand the terminal, I can accomplish my tasks more efficiently because it has a higher level of control.
Using Understand reminds me of using Linux. On the surface, Linux can behave similarly to OSX and Windows. At least, the distributions of Linux I’ve used have a graphical interface with things like a file explorer, a text editor, and a web browser, but the power comes from using the terminal, that layer beneath the GUI where I have more control.
Similarly, on the surface, Understand’s graphical user interface behaves an awful lot like an IDE. It has a lot of the things IDEs have, like an editor and a project browser. However, the power of Understand isn’t mimicking some aspects of an IDE, it comes from how Understand represents your code. Learning that is a lot more work than learning another IDE. Understanding the Understand paradigm will open up a whole new level of control and it’s definitely worth it!
Entities
Let’s start from the editor. Code editors usually have syntax highlighting, meaning language keywords are displayed differently. Even in this blog article, the int in the following line is a different color because it is a keyword in C/C++:
int x = foo();Some code editors, including Understand, support semantic highlighting. Semantic highlighting displays foo differently than x because foo is a function and x is a variable. The knowledge that x is a variable and foo is a function is part of that layer underneath the GUI.
In Understand’s paradigm, variables and functions are referred to as entities. At its simplest, an entity has a name and a kind. At this point, it might not seem very impressive. Anyone familiar with the language could tell that foo is a function with a glance. Even the code styling in this blog article displayed foo differently than x. The parentheses are a giveaway.
The entity kind is more detailed than just “function.” For instance, is foo static? Or, maybe this line is inside a member function. In that case, foo might be public, private, protected, virtual, or constant. Actually, can we even be sure foo is a function and not a macro? The entity kind contains all that information. Understand can use it to display virtual functions differently from other member functions which can be different from non-member functions.
Using Entities
Semantic highlighting is one feature that relies on entity kinds. It’s part of the graphical layer, the kind of thing that multiple IDEs support. If all I’m interested in is semantic highlighting, I don’t need to understand the paradigm. Why would I care about accessing the entities directly?
A casual user of Understand might not need to access entities directly. A lot of the common things you’d do with entities are part of the graphical user interface layer. For example, you might want a list of all the functions in your project. Or the ability to find the global object “foo” while ignoring the function that’s also called “foo.” The Entity Filter supports both of those tasks. The combo box at the top has a set of predefined entity kind filters, and the line edit below it allows filtering based on the entity name.
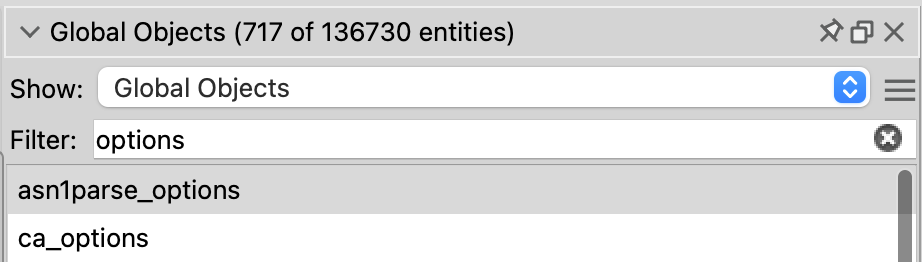
There’s also a more powerful version of the Entity Filter called the Entity Locator. The Entity Locator has search boxes for additional fields such as the entity kind:

These graphical interfaces wrap functionality that you have access to directly from the APIs. For example, in Python:
import understand
import re
db = understand.open("openssl.und")
# Create a regular expression that is case insensitive
searchstr = re.compile("options",re.I)
for ent in db.lookup(searchstr,"Global Object"):
print (ent)
If the end goal is that list of functions or finding that global object named “foo”, then the graphical interface is sufficient. Writing a script is overhead. But, if that list is a means to an end, then it’s time to dive into that layer beneath the GUI. Here are some possibilities:
- Enforcing naming standards, like functions are lower camel case but classes are upper camel case. There are CodeChecks for this.
- Finding a complex kind, for instance a global object that is not static. Impossible from the graphical user interface, but a small update to the above script “global object” -> “global object ~static”
- Using the list of entities as input for further processing. For example, intersecting the list of all header files named test with the list of files changed in a git commit.
References
To be honest, though, entity names and kinds are a small part of the power of Understand. The real strength comes from references. Let’s look at that line of C/C++ code again:
int x = foo();We know that the two entities on the line are x and foo. But what is happening to x and foo? The variable x is defined and initialized to a value. The function foo is called. These actions are called references. A reference ties an action to an entity at a particular location in the code. In Understand, the action is the reference kind. Like an entity kind, it is represented as a string. So “Call”, “Define” and “Set Init” are all reference kinds.
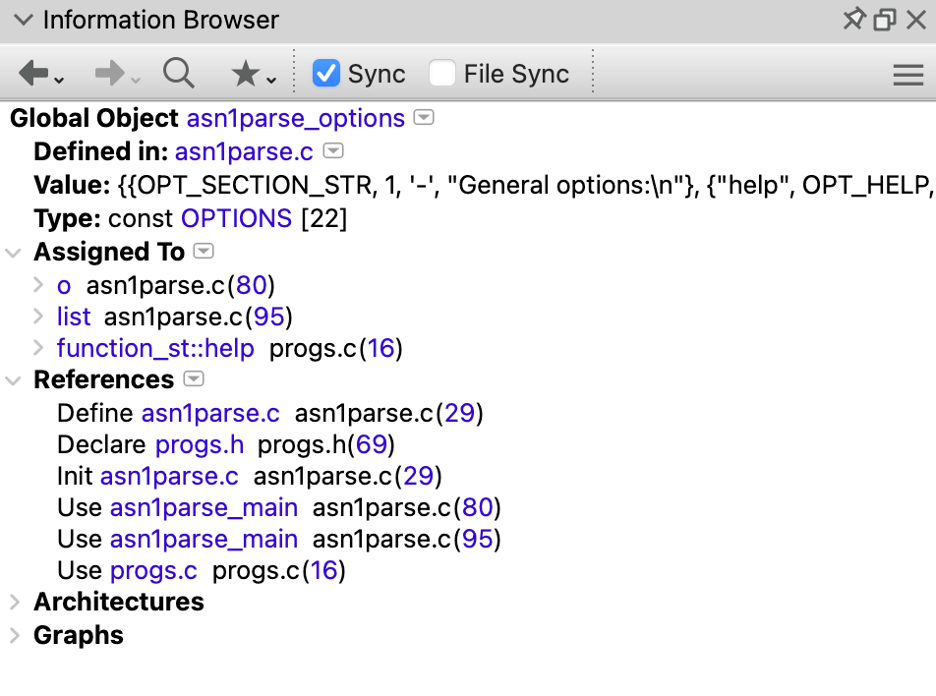
Understand displays this reference information in the Information Browser. For example, the global object shown in the screenshots above has this information:
Using References
Retrieving the references for a particular entity is not unique to Understand. An IDE that has a “Go to Definition” or “Go to Declaration” is using the same kind of information. Some IDEs even have the option to find all the references. If that’s the final goal, then Understand would be just another view onto the same information. But the point isn’t the view. The point is the paradigm. Once you have references, what can you do with them? Well, here are some of the things Understand’s graphical user interface does with references:
- Understand displays those references in a graphical format, like call trees or include trees.
- Understand uses references to calculate dependencies. For example, that call reference to foo() means the file containing that line depends on the file where foo is defined.
- Understand uses references for refactoring tools since knowing everywhere an entity is referenced means all those references can be updated programmatically.
- Understand’s CodeChecks are written as scripts. Some examples possible with just entities and references are detecting unused functions and variables, checking for virtual calls in constructors and destructors, and finding variables that should be constant.
The built-in features might be enough but they don’t have to be. To get started, you can write plugins that are run by Understand. For example, these articles describe how to write your own graphs that can be displayed and exported by Understand:
- Making a Custom Call Tree
- Making a Custom Architecture Tree
- Making a Dependency Graph with Custom Dependencies
- Making a Custom Cluster Graph
- Making a Custom IOCTL Calls Tree
- Visualizing Shared Tasks
And this article describes a custom CodeCheck Plugin. But you don’t have to stick with plugins. You can write custom scripts to directly solve your own questions.
- The search script mentioned above was based only on the entity name and kind, but you could also limit your search by references. For example, only global objects that have at least one set reference or only functions with both call and called by references.
- Suppose you’re a quality assurance engineer. You can start with a list of changed files from git, find those files as entities, and use “define” references to find all the functions defined in those files. You can take it a step further and follow the “called by” references on those functions to find the test functions that might need to be updated.
- You can generate custom exports for use with other programs. I recently exported the number of includes and included by references for every file in a project to use with Microsoft Excel to make histograms.
Metrics & Control Flow
You may have noticed that CodeCheck has been mentioned twice. With just entities, only checks based on entity information like the name check are possible. With references, more checks become possible, like unused variables and functions. But there are some checks that rely on more information. For example, how does a check enforcing a maximum cyclomatic complexity work? Or the check for unreachable code? There are two other sources of information in the Understand paradigm that are worth mentioning.
The first is metrics. Understand stores metrics about each entity such as the number of lines of code or the cyclomatic complexity. Metrics allow checks like the one that enforces a maximum cyclomatic complexity. It’s also the information behind the charts on Understand’s welcome page and Project Overview page. From the API you might:
- Sort that list of functions you made earlier by cyclomatic complexity
- Shade a call tree by cyclomatic complexity, like described in this article
- Calculate your own metrics like this script for Halstead and Maintainability Index.
The second information source is control flow information. The control flow graph represents possible paths through the code. The CodeCheck for unreachable code uses control flow information. The control flow information can be graphed in Understand and is used for the UML Sequence diagram to find conditionals and loops. From the API, you might:
- Implement a virtual debugger, like this article
- Customize your own control flow graph plugin
- Calculate your own metrics that rely on knowing paths through the code.
Conclusion
So far, the examples have been for small scripts to solve specific problems, but Understand can become part of your overall process too. Here are some examples:
- This article describes how the Navy uses Understand to enforce a custom coding standard. Like the Navy, you can request custom scripts or features from our engineers.
- This article describes how we use Understand to notify our engineers when a commit violates coding standards.
- One group developed scripts to create custom architectures (tree-like structures that group entities) and uses those architectures for metrics and dependencies. This article describes a similar custom architecture for dependencies but on a smaller scale. Also check out these articles on architectures.
- Another group writes their own custom reports that can be run from the Understand GUI. Learn more about interactive reports here.
- A code review group uses annotations to take notes on code without editing it. Annotations follow entities so the notes can stay with the code over time. Learn how to use annotations here.
Understand acts a lot like an IDE so it’s easy to think that it’s only an IDE. However, Understand is really a paradigm for understanding your code. The graphical user interface is just the surface. The real power comes from the paradigm.





